
Model korpusově koncipovaného slovníku Jana Čepa v kontextu české autorské lexikografie a kvantitativní analýzy literárního jazyka
Richard Změlík
[Články]
A corpus-based model for the Jan Čep dictionary in the context of Czech authorial lexicography and the quantitative analysis of literary language
The study presents a model for a dictionary based on the work of Jan Čep in the context of Czech authorial dictionaries and quantitative research on fiction texts. Designed to make a functional link between perspectives from linguistics and literary criticism perspectives, the dictionary with its conception, purposes and type is a part of the development of Czech authorial lexicography. It is the first project of its kind among frequency author-based dictionary that is aimed at providing tools for literary criticism to pre-interpret literary texts in a functional, objectivized way. The dictionary, however, is not (and cannot be) a substitute for the actual critical analysis of literary texts.
Key words: corpus linguistics, frequency dictionary, Jan Čep, lexicography, literary criticism, narratology, textology
Klíčová slova: korpusová lingvistika, frekvenční slovník, Jan Čep, lexikografie, literární věda, naratologie, textologie
[1]1 Úvodem
V českém prostředí se autorská lexikografie reflektovala od 60. let 20. století. Její rozvoj souvisí především s nástupem výpočetní techniky, která umožnila strojové zpracování jazykového materiálu. Z tohoto důvodu lze u nás hovořit především o frekvenčním typu autorského slovníku, který se zvláštním způsobem mohl kombinovat s typem konkordančním. Naopak zde chybí druh výkladového slovníku nebo tzv. autorský thesaurus, popřípadě tradiční konkordanční slovník, jak se s nimi setkáváme v zahraničí. Oldřich Králík ve své stati Autorské slovníky, ve které přehledově uvádí některé významné práce tohoto zaměření v zahraničí, s odvoláním na článek Christy Dillové (1959, s. 345) konstatuje, že autorka v něm odkazuje na záměr vybudovat Máchův slovník (viz Králík, 1961, s. 240). Dnes lze pouze hypoteticky usuzovat, že mohlo jít o podobný lexikografický projekt, který představují velké zahraniční výkladové slovníky. [114]Dillová ve svém článku uvádí, že hlavním problémem jeho realizace byl příliš individuální básníkův styl. Tato skutečnost nepřímo dokládá, že autorské slovníky byly sestavovány nikoli pro účely literárněvědného bádání, ale především kvůli snaze systematicky mapovat národní jazykovou situaci.
2 České autorské slovníky
Prvním českým autorským slovníkem je Konkordanční a frekvenční index k Slezským písním Petra Bezruče, který zpracoval kolektiv pod vedením Jitky Štindlové v mechanografické laboratoři Ústavu pro jazyk český ČSAV v Praze roku 1969. Jak je zřejmé z názvu, kombinuje se zde typ frekvenční a konkordanční, ovšem způsobem, jenž vyplývá ze specifického strojového zpracování materiálu. Ve výsledku je každé lemma realizováno číselnou matricí, ve které jednotlivé pozice nesou samostatnou informaci o lokalizaci příslušné lexikální jednotky v díle. Chybí zde jakýkoli výkladový aparát, interpretační lexikografický metatext či dokladové citační pasáže. Praktické užití takovéto práce je oproti „klasickým“ výkladovým slovníkům proto nutně omezené. Na druhé straně se ovšem jedná o zajímavou ukázku možností dobové strojové analýzy v lexikografii. Děrnoštítková metoda, která zde byla použita, dovoluje oproti tradičně sestaveným slovníkům variabilní řazení lexikálních jednotek. Ve výsledku potom může mít slovník takovou podobu, která vyplyne ze zvoleného kritéria řazení; lze se například soustředit na lexikální rovinu v konkrétním textu, strofách, verši apod. a sledovat základní frekvenční či kvalitativní obsazení definovaných úseků, které je možné posléze mezi sebou srovnávat. Tyto možnosti analýzy jsou spoludefinovány jmenovaným typem strojového zpracování autorského jazyka. Později, zejména s rozvojem korpusových nástrojů a sofistikovanějších statistických postupů, dojde k přirozenému rozšíření možností, které lingvistika i autorská lexikografie budou mít k dispozici.
V roce 1993 vydal Petr Holman autorský slovník Frequenzwörterbuch zum lyrischen Werk von Otokar Březina. Tuto práci autor charakterizoval rovněž ve studii Frekvenční slovník básnického díla Otokara Březiny, která vyšla v Naší řeči v roce 1988, slovy: „základním posláním tohoto slovníku je podat celkový obraz úplné slovní zásoby Březinova básnického díla, tedy všech veršů, které byly básníkem zařazeny do definitivního vydání jeho díla, Tajemnými dálkami počínaje a dvěma posmrtně objevenými básněmi (Za všechno díky, Návrat) konče. Důležitým cílem slovníku je také, aby poskytl všechny číselné údaje (absolutní a relativní frekvence, distribuční koeficienty, údaje o disperzi atd.) potřebné pro další kvantitativní výzkum Březinova jazyka, ale šíře i jazyka devadesátých let a jazyka obecně.“ (Holman, 1988, s. 43) Holmanův příklad dokládá, že frekvenční autorský slovník lze koncipovat různými způsoby. Vedle základní absolutní frekvence lemmat je sledována relativní frekvence, která umožňuje vzájemnou komparaci dvou nestejně velkých textových bloků, které představují [115]Březinovy básnické sbírky. U Holmana jsou navíc jednotlivé hodnoty uspořádány tak, aby i ony byly vzájemně porovnatelné, čehož autor dociluje tak, že vždy po skupině deseti lemmat uvádí součtové a kumulativní frekvenční hodnoty. Takovéto rozvržení nabízí operativnější zacházení a orientaci s frekvencemi lexikální jednotky (lemmatu), které lze sledovat v rámci definovaných frekvenčních skupin.
Nejnovějšími pracemi z oblasti české autorské lexikografie jsou Slovník Karla Čapka (2007) a Slovník Bohumila Hrabala (2008). Obě publikace vznikly na půdě Českého národního korpusu pod vedením Františka Čermáka. Jedná se o první české autorské slovníky, které zpracovávají kompletní slovesnou tvorbu daných autorů, tzn. vedle textů umělecko-literárních i autorskou korespondenci či esejistiku nebo publicistiku. Metodologicky tyto práce vycházejí z korpusového zpracování jazykového materiálu s tím, že tištěné verze slovníku představují frekvenční distribuci lemmat dle žánrových kritérií. V případě Čapkova slovníku je autorský korpus segmentován na šest subkorpusů, Hrabalův slovník pracuje se čtyřmi subkorpusy. Kromě dílčích frekvencí je uvedena i celková frekvence lemmatu.
| KČ | BH |
| Próza | Delší próza |
|
| Kratší próza |
| Poezie | Poezie |
| Drama |
|
| Publicistika | Publicistika |
| Odborná literatura |
|
| Korespondence |
|
Tab. 1 Žánrové dělení ve Slovníku Karla Čapka (KČ) a Slovníku Bohumila Hrabala (BH)
Vymezení těchto subkorpusů se řídí primárně lingvistickými kritérii a sleduje především žánrové zaměření textů. V tomto ohledu se jedná o metodologickou analogii ke způsobu, jakým je strukturován Český národní korpus (ČNK), který tvoří tři relativně vyvážené stylově-funkční oblasti národního jazyka; publicistika je zastoupena 33 %, beletrie 40 % a odborná literatura 27 %.[2] Každá z nich je potom jemněji segmentována a parcelována na podskupiny.
Využitelnost obou autorských slovníků má však i určitá omezení vyplývající z jejich koncepce a rozvržení. Platí zde, že vedle srovnání lexikostatistických hodnot mezi jednotlivými subkorpusy (spolu s dalšími statistickými hodnotami, jež jsou součástí elektronických verzí těchto prací) lze srovnávat komplexní lexikální distribuci z hlediska porovnávání mezi jednotlivými autorskými slovníky a jejich subkategoriemi, stejně jako mezi celými autorskými korpusy a ČNK. [116]Jestliže nám autorský slovník dovoluje učinit si představu o slovníku u konkrétního autora, a to na pozadí lexikonu jiného autora nebo národního jazyka, o něco komplikovanější je využití těchto slovníků v literárněvědné práci. Je ovšem třeba zopakovat, že slovníky nebyly koncipovány pro literárněvědné účely, na čemž nic nemění ani způsob jejich strukturace do žánrových skupin.
V současnosti existují také další projekty, které primárně zpracovávají autorské lexikum. Od 90. let 20. století je v přípravě slovník Jaroslava Seiferta, který zpracovává skupina kolem Svatavy Machové a Ladislava Janovce.[3] Na olomoucké katedře bohemistiky FF UP je pod vedením Petra Pořízky rozpracován autorský korpus české esejistiky, který započal svoji činnost excerpcí Březinovy knihy Hudba pramenů a textem Ladislava Klímy Svět jako vědomí a nic (srov. Pořízka – Schäfer, 2010). Na témže pracovišti potom od roku 2012 vzniká slovník Jana Čepa, jenž si klade některé specifické otázky související s jeho literárněvědným využitím (viz dále).
3 Ohlédnutí za kvantitativním výzkumem uměleckého jazyka
V kontextu současného literárněvědného myšlení nebývá obvyklé, aby se k analýze literárních uměleckých děl (narativních či nenarativních) využívaly takové postupy, se kterými se přednostně setkáváme v lingvistice, v níž jsou i metodologicky i problémově definovány. Máme na mysli současné možnosti elektronického korpusu a jeho statistických nástrojů. Jak upozornil již František Čermák, korpus není synonymem pro pouhou katalogizaci, ale je především nástrojem, který otevírá nové možnosti při zkoumání jazyka. V prvé řadě se jedná o snahu věcně a reprezentativně podpořit odbornou argumentaci konkrétními údaji a informacemi o sledovaném jevu, které lze objektivizovat, a současně určit, do jaké míry se jedná o jevy časté, rozšířené či progresivní, nebo naopak jevy ustupující a ocitající se spíše na periferii jazyka. Na tomto místě ovšem nehodláme vést rozpravu o možnostech a limitech jazykového korpusu pro lingvistiku, ale pokusíme se zamyslet nad možnostmi využití elektronického korpusu a jeho principů v literární vědě. Dříve, než tak učiníme, připomeňme stručně vývoj kvantitativního zkoumání uměleckého jazyka u nás.
[117]Aplikace lexikostatistických postupů v lingvistice – a okrajově v literární vědě – má svoji dlouholetou tradici.[4] Vedle autorských slovníků, které ovšem – jak bylo naznačeno – sledují zejména lingvistické zájmy, můžeme odkázat na některé časopisecky publikované texty, např. studie M. Těšitelové (1948, 1955, 2000) k jazyku Karla Čapka. Obecnější zaměření mají další práce Těšitelové (1968, 1974). Na výsledky jejího bádání navazuje Mojmír Klivar (1984).
Zásadní význam měla práce Lubomíra Doležela (1965), který ve svém literárněvědném bádání vycházel z podnětů lingvistického strukturalismu, jež se mj. v odkazu na Benseho (1962) pokusil napojit na statistické metody.[5] Doležel ve své studii přináší řadu dobově nových poznatků zejména z oblasti tzv. informačněteoretické estetiky, která propojuje sémiotiku s matematickými postupy (Doležel, 1965).
Uvedené publikace dokládají nejen dobový zájem o možnosti strojové analýzy jazyka, ale rovněž předkládají základní (lexiko)statistické výsledky, které z takto pojatého výzkumu básnického jazyka vyplynuly. Těšitelová například zkoumá proporcionální rozložení mezi slovními druhy, které tvoří syntakticko-lexikální skupiny.[6] Ačkoli ne všechny texty směřují k literárněvědným otázkám se stejnou intenzitou, jsou pro nás přesto uvedené poznatky i dnes důležité a inspirativní, neboť se tu prolínají lingvistické aspekty s některými literárněvědnými oblastmi. To se týká například statistické charakteristiky tematického plánu, bohatství slovníku, opakování slov apod. Především ale tyto publikace naznačují možnosti, jak dosažených výsledků využít v literárněvědné oblasti. Doležel např. pomocí kvantitativních metod sleduje hranici mezi prostředky jazykové automatizace a aktualizace, Těšitelová se kromě jiného věnuje rozložení lexikální zásoby ve vybraných textech z hlediska jejich frekvenční distribuce na ose mezi centrem a periferií. Kromě jiného při tom pracuje s hodnotami, jichž lze i dnes smysluplně využít v literárněvědné práci. Mezi ně patří měření bohatství slovníku, disperze nebo koncentrace slovníku (viz Těšitelová, 1974, s. 60n.).
Pro všechny uvedené práce, přestože excerpují umělecký slovesný materiál, ovšem platí, že vlastní literárněvědné hledisko je ve výsledku podřízeno především lingvistickému zájmu. Literární a jiné texty zde slouží jako dostupný [118]jazykový zdroj, který navíc umožňuje provádět kvantitativní analýzu na funkčně diferencovaném textovém materiálu. Tím, že svou analýzou prokazují individuální rozdíly mezi jazykovými kategoriemi na gramaticko-lexikální úrovni, jsou tyto studie schopny poskytnout důležitou oporu v argumentaci spočívající především na objektivizaci určitých jazykových jevů. Literárněvědné nároky na tuto kvantitativní metodologii formulují především zmiňované studie L. Doležela (1965) a M. Těšitelové (1955), která se v ní věnuje sémantické analýze lexikální oblasti v Čapkově próze Život a dílo skladatele Foltýna s ohledem na charakteristiku postav a referenční strategie vypravěče (viz Těšitelová, 1955, s. 298). L. Doležel, inspirovaný podněty informačněteoretické estetiky a generativní lingvistiky, naopak usiluje za pomocí statistických a matematických metod o exaktnější stanovení hranice mezi normovaným jazykem a jazykem aktualizovaným a na tomto pozadí o vymezení dynamiky změn, kterými prochází vývoj básnického jazyka. Zajímavým příkladem využití kvantitativních metod v souvislosti s publicistikou je i nedávno otištěná studie Jany Davidové Glogarové a Radka Čecha (2013), ve které její autoři usilují o objektivizovanou konfrontaci rozdílných skupin textů na základě poměřování hodnot tzv. tematických slov, jejich výskytu a síly (tzv. tematické váhy), jež určuje tematickou koncentraci textu.
V současné době nicméně literární věda kvantitativní či korpusové postupy příliš nereflektuje. Je to kromě jiného dáno jednou z jejích současných a výrazných orientací, která zdůrazňuje zaměření na aktuální témata (postkolonialismus, genderová studia, ideologické strategie umělecké reprezentace, výzkum kulturní paměti apod.), jejichž orientace je spíše ideologická než vyhraněně metodologická.
4 Model slovníku Jana Čepa
Jestliže se hodláme pokusit znovu využít kvantitativní postupy a analýzy v literární vědě, děje se tak v situaci, kdy jsou dostupné nové metody, které dříve k dispozici nebyly. Jedná se především o postupy, kterými dnes běžně disponuje jazykový korpus a jež pro své analytické účely využívá korpusová lingvistika. Těmito možnostmi je rovněž inspirován koncept Čepova slovníku.
Základní rozvržení autorského slovníku Jana Čepa vyplývá z úsilí excerpovat celé autorovo dílo, tedy texty různé žánrové povahy. Z důvodů literárněvědných však nelze korpus z něho odvozený segmentovat způsobem, který byl použit v případě Čapkova nebo Hrabalova slovníku, ale je třeba definovat jednotlivé subkorpusy s ohledem na přesnější (literárněvědná) žánrová kritéria. Nejjednodušší způsob, který se zdá být relevantní jak z lingvistického pohledu, tak z literárněvědného hlediska, je stratifikovat autorský korpus do dvou oblastí podle fikčního příznaku textů a tyto dále členit. Názorně situaci demonstruje tabulka 2.
Základní rozdělení Čepovy slovesné tvorby má dvojí rovinu. První tvoří subkorpus tzv. fikčních narativů, tj. textů s příznakem fikčnosti (+FIK), do druhé skupiny, která je dále žánrově segmentována, náleží ostatní texty (–FIK). Jak vyplývá
| –FIK | ||||
| < dvojí domov > | eseje a úvahy | korespondence | deníky | ostatní (nekrology, přednášky, poznámky, komentáře) |
| < vigilie > | ||||
| < zeměžluč > | ||||
| < letnice > | ||||
| < děravý plášť > | ||||
| < hranice stínu > | ||||
| < modrá a zlatá > | ||||
| < tvář pod pavučinou > | ||||
| < polní tráva > | ||||
| < cikáni > | ||||
| < časopisecké texty z 20. let > | ||||
| < časopisecké texty z 30. a 40. let > | ||||
Tab. 2 Taxonomie Slovníku Jana Čepa. Slovník je členěn do dvou základních subkorpusů definovaných příznakem fikčnosti (+FIK/–FIK). Oblast tzv. fikčních narativů (+FIK) je dále chronologicky segmentována (dle prvního vydání) na jednotlivé povídkové soubory (subkorpusy).
z tabulky 2, je toto členění založeno na dvou základních aspektech. Zaprvé vydělit autorovy texty, které jsou v pravém slova smyslu texty beletristickými, od ostatních. Rozlišovacím kritériem je jejich fikcionalita, jež je chápána v intencích teorie fikčních světů.[7] Na této úrovni je autorský korpus segmentován dle žánrových kritérií, která umožňují vzájemná srovnávání statistických a korpusových hodnot s tím, že tato žánrová distribuce respektuje literárněvědné definice žánrů. Kromě zjevného významu takovéhoto členění spočívá jeho funkčnost rovněž ve zjišťování statistických a korpusových poměrů a vztahů mezi těmi žánrovými třídami, jež – zejména v případě Čepa – tvoří užší skupinu. To se týká jeho esejistické tvorby, která se prolíná s prozaickými texty. Formální kritéria, kterými lze definovat jednotlivé žánry, dovolují stanovit hranice mezi jednotlivými subkorpusy. Srovnáváním situace v rámci jednotlivých subkorpusů bude možné sledovat, jakým způsobem Čep v rámci žánrových skupin pracuje s jazykem, resp. jaké jazykové (lexikální, gramatické, syntaktické) strategie volí a používá s ohledem na typ textu, resp. žánru. Na této rovině bude rovněž možné využít slovník i pro srovnání s kvantitativními a korpusovými hodnotami Čapkova a Hrabalova slovníku,[8] [120]popřípadě se situací v ČNK. Tuto skutečnost dovoluje i metoda, kterou má být slovník Čepova díla v korpusové podobě zpracován a jež je kompatibilní se způsobem, jakým jsou realizovány oba zmíněné slovníky i ČNK. Čepovy texty tedy při převodu do elektronické podoby budou opatřeny identifikačními údaji dle standardů používaných při zpracování textů pro ČNK a následně lemmatizovány. Čepův slovník bude spojovat frekvenční a korpusovou metodu.
Jádro slovníku ovšem tvoří množina literárně-uměleckých textů, tedy těch s příznakem fikčnosti. Mezi roky 1926–1948[9] publikoval Čep osm povídkových souborů, jeden román (Hranice stínu) a řadu drobnějších povídek, jež byly publikovány pouze časopisecky. Cílem projektu Čepova slovníku je systematizovat tuto oblast tak, aby ji bylo možné funkčně zpracovat metodou kvantitativní a korpusové analýzy. To předpokládá rozčlenit jmenovanou Čepovu tvorbu do souměřitelných kategorií, subkorpusů. Jelikož v našem případě nesledujeme textologické hledisko, ale zajímá nás výhradně hledisko kvantitativní, vycházeli jsme z důvodu maximální možné úplnosti korpusu v této fázi budování slovníku z prvních vydání jednotlivých povídkových knih. Čep některé své knihy postupně revidoval, tzn. v dalších vydáních z nich vypouštěl vybrané povídky (viz tabulka 3).
Po sestavení jednotlivých subkorpusů, které doplňují i samostatné subkorpusy textů, které Čep publikoval pouze časopisecky,[10] dostáváme z kvantitativního hlediska úplnou množinu textů definovanou příznakem fikčnosti (+FIK). Každý z těchto subkorpusů lze vydělit pozitivně ve dvou ohledech. První je definován hranicí celkového textového rozsahu díla (povídkového souboru nebo povídky v případě pouhého časopiseckého zveřejnění), druhý vyplývá ze sestavení tzv. relativní chronologie, která má význam pro další kvantitativní interpretaci. Relativní chronologii názorně předvádí obrázek 1.
Schéma znázorňuje dvě osy (A, B), nad, resp. pod nimi jsou vyznačeny desetiletí a rok Čepova odchodu do exilu (1948). Na ose A jsou vyznačena první vydání povídkových souborů a vydání časopiseckých próz. Číslo vyjadřuje počet povídek v souboru nebo počet povídek, které v daném roce Čep časopisecky publikoval. Na ose B je zanesena tzv. relativní chronologie.[11] Představuje rozmezí vzniku jednotlivých povídkových souborů a skupin definovaných časopi-
| VIGILIE (1928) | ZEMĚŽLUČ (1931) | DVOJÍ DOMOV (1969) | VIGILIE (1969) | ZEMĚŽLUČ (1969) | |||
| DVOJÍ DOMOV | VIGILIE | ZEMĚŽLUČ | |||||
| Domek | Na rozchodnou | Domek |
| Starcův smích | Domek |
| Starcův smích |
| Bouře | Zbloudilý** |
|
| Hoře z lásky | Bouře | Zbloudilý | Hoře z lásky |
| Smrt ševce Nerušila | Rozárka Lukášová |
| Rozárka Lukášová | Veselá pohřební |
| Rozárka Lukášová | Veselá pohřební |
| Vzpoura | Husopas |
| Husopas | Můra |
| Husopas | Můra |
| Dvojí domov | Čí bude vítězství*** | Dvojí domov | Přičinlivá rodina | Starosvětská | Dvojí domov | Přičinlivá rodina |
|
| Kozlovice | Zelené jiskry | Kozlovice |
| Lucie Laurová | Kozlovice |
| Lucie Laurová |
| Dobyvatel | Vigilie**** |
| Vigilie | Albína Drůzová |
| Vigilie | Albína Drůzová |
| Justýnka* | Epilog |
|
| Cesta na jitřní |
|
| Cesta na jitřní |
| Peněženka |
| Peněženka |
| Přízraky | Peněženka |
| Přízraky |
| Do města |
| Do města |
|
| Do města |
|
|
| Mámení |
|
|
|
|
|
|
|
| Křepelka |
|
|
|
|
|
|
|
| Elegie |
| Elegie |
|
| Elegie |
|
|
Tab. 3 Tabulka zobrazuje obsahové rozdíly mezi různými vydáními povídkových souborů. Pro účely korpusového a kvantitativního zpracování Čepova (sub)korpusu fikčních narativů zakládáme jednotlivé subkorpusy, tj. povídkové soubory, na maximálně relevantním rozsahu jednotlivých knih. V případě subkorpusu Dvojí domov je jeho základem první vydání povídkového souboru z roku 1926.
* Povídka Justýnka byla poprvé otištěna v roce 1926 v moravskoslezském deníku Besedy, jak uvádí M. Trávníček, který ve své čepovské monografii rovněž dodává, že se jednalo o jedinou povídku, kterou Čep ze svých juvenilií zařadil do oficiálního povídkového souboru. (Trávníček, 1996, s. 24–25) Jak je ovšem z tabulky patrné, ve druhém vydání Dvojího domova ji Čep vypustil.
** Původně pod názvem V předvečer neznámé katastrofy; povídka byla otištěna v časopise Černá země (Trávníček, 1996, s. 41).
*** Povídka Čí bude vítězství je ve 2. vydání přetištěna pod názvem Přičinlivá rodina.
**** Původně pod názvem Kříže u cest (Trávníček, 1996, s. 41).
seckou tvorbou.[12] Zejména zobrazení na ose B umožňuje takovou interpretaci, která statistické a korpusové údaje bude vyhodnocovat s ohledem na chronologickou situaci, a zejména na vztahy mezi subkorpusy, které z této relativní chro-
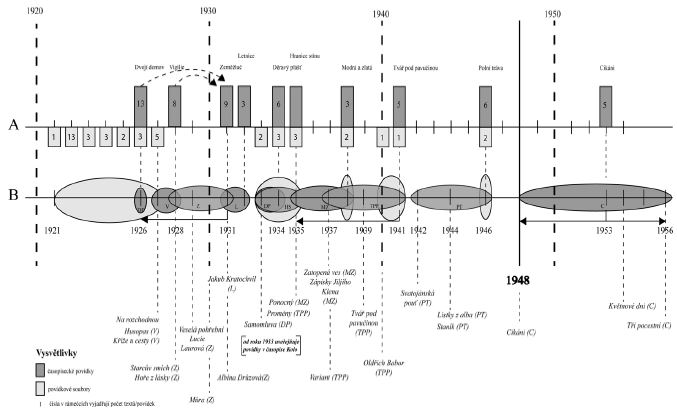
Obr. 1 Schematické zobrazení tzv. relativní chronologie vzniku jednotlivých povídkových souborů. Na ose A jsou vyznačeny povídkové soubory dle jejich prvního knižního vydání. Osa B je rekonstrukcí relativní chronologie vzniku každé povídkové knihy. Tvůrčí geneze, která má v tomto případě pouze formální relevanci, nikoli textologickou (!), je vyvozována ze zjištění učiněných Mojmírem Trávníčkem a dále z úplné rekonstrukce Čepovy bibliografie, kterou provedl Tomáš Kubíček. (Bude publikována v chystané Kubíčkově monografii o Janu Čepovi.) Osa B slouží jako „klíč“ pro interpretaci (komparaci) korpusových a kvantitativních hodnot mezi jednotlivými subkorpusy.
nologické situace vyplývají. Jinými slovy, můžeme porovnávat texty z hlediska jejich časové následnosti i souslednosti a zjišťovat, jak se tyto poměry projevují v jazykové oblasti. Tak nás například bude zajímat, jak se k sobě mají nejen soubory Dvojí domov, Vigilie a Zeměžluč (vztah bezprostřední následnosti), ale i v jakém poměru jsou Dvojí domov a časopisecká próza, která tvoří subkorpus vymezený lety 1921–1927. A stejně tak lze srovnávat i ty části, které spolu zdánlivě nesouvisejí (vztah volné následnosti, např. subkorpusy Letnice, Modrá a zlatá apod.) a ve schématu představují relativně samostatné oblasti. Podobně při srovnávání jazykové situace u subkorpusů Děravý plášť a Hranice stínu budeme moci kvantitativní hodnoty interpretovat na pozadí skutečnosti, že Čep v době, kdy koncipoval první knihu, pracoval vlastně již i na knize druhé atd. Bude nás tedy zajímat nejen lineární vývojová posloupnost textů, ale i jejich synchronie. Osa B nám de facto poskytuje „klíč“ k interpretaci statistických informací takovým způsobem, aby mohly být využitelné v literárněvědné práci.
[123]5 Pokus o jemnější strukturaci Čepova slovníku
Takto koncipovaný slovník již může být prospěšný literárněvědnému zkoumání tematiky (na jazykové úrovni) a intertextuality. Zůstává ovšem otázkou, zdali je možné segmentovat korpus fikčních narativů na nižší rovině takovým způsobem, aby byla zaručena metodologická koherence s principy korpusového zpracování materiálu a jeho případné stratifikace. Jedná se zde o problém, jak vyčlenit nižší oblasti, než jsou ty, které jsou definovány hranicí knihy nebo textu, avšak způsobem, abychom v maximální možné míře dokázali při takové segmentaci eliminovat subjektivní činitele. Zamýšlená segmentace tedy musí být provedena s ohledem na formálně stanovitelné hranice mezi potenciálními segmenty. Tento požadavek přirozeně vyplývá z povahy lexikostatistické analýzy, která vyžaduje dodržet formalizovaná kritéria. Možné řešení dané situace nabízí aplikace taxonomie narativních promluv vypracovaná Lubomírem Doleželem (1993). Předností Doleželovy klasifikace je, že vychází z lingvisticko-sémantických aspektů, kterými jsou jednotlivá promluvová pásma ve fikčním narativu realizována a jejichž markery vydělují jednotlivé promluvové typy. Následující tabulku, která tuto skutečnost názorně zobrazuje, přebíráme ze jmenované Doleželovy monografie (viz Doležel, 1993, s. 39):
|
| znaky P (V) | znaky P (P) |
| 1. přímá řeč |
| grafické |
|
| gramatické | |
|
| výpovědní | |
|
| sémantické | |
|
| slohové | |
| 2. neznačená přímá řeč | grafické | gramatické |
|
| výpovědní | |
|
| sémantické | |
|
| slohové | |
| 3. polopřímá řeč | grafické | výpovědní |
|
| gramatické | sémantické |
|
| slohové | |
| 4. smíšená řeč | grafické | výpovědní |
| gramatické | sémantické | |
| výpovědní | slohové | |
| sémantické |
| |
| slohové |
| |
| 5. objektivní vyprávění | grafické |
|
| gramatické |
| |
| výpovědní |
| |
| sémantické |
| |
| slohové |
|
Tab. 4 Doleželova taxonomie promluv ve fikčních narativech. Doležel vymezuje pět kvalitativně odlišných příznaků, jejichž přítomnost/nepřítomnost definuje promluvový typ ve fikčních narativech.
[124]Tuto Doleželovu taxonomii ovšem nelze převzít doslova. Důvodem je především jmenovaný důraz na formalizovaná kritéria segmentace jednotlivých promluvových rovin. V případě některých narativních promluv totiž nelze formálně jednoznačně určit daný typ promluvy, což se týká především smíšené řeči, kterou disponuje subjektivní er-forma. Převedeme-li Doleželovo schéma do tabulkového formátu s tím, že u jednotlivých promluvových typů vyznačíme pomocí číselné hodnoty přítomnost jednotlivých distinktivních rysů, se kterými Doležel pracuje při vymezení promluvových pásem, dostaneme následující přehled.
|
| znaky P (V) | znaky P (P) | distinkce |
| 1 | 0/5 | 5/5 | pozitivní |
| 2 | 1/5 | 4/5 | pozitivní |
| 3 | 2/5 | 3/5 | pozitivní |
| 4 | 5/5 | 3/5 | negativní |
| 5 | 5/5 | 0/5 | pozitivní |
Tab. 5 Klasifikace Doleželových promluvových typů dle pozitivní binární distribuce (distinkce) příznaků. Promluvový typ 4 (smíšená řeč) je z tohoto hlediska konfúzní.
Jak vyplývá z tabulky 4, jedná se celkem o pět odlišných rysů, které náleží do různých vrstev strukturního popisu jazyka. Z tabulky 5 je zřejmé, že v případě čtvrtého promluvového typu dochází k narušení jednoznačně binární distribuce těchto rysů vyjádřené buď přítomností (pozitivní příznak), nebo nepřítomností (negativní příznak) daného rysu. Smíšená řeč je podle Doleželovy klasifikace založena na konfúzi mezi rysy pásma vypravěče a postavy, které konkrétně tvoří markery výpovědní, sémantické a slohové. Jako negativní jsme proto označili promluvový typ 4 (smíšenou řeč), neboť se v ní překrývají znaky pásma vypravěče – P(V) a postavy – P(P). Jinými slovy, je obtížné definovat tento promluvový typ výhradně formálně. Jeho určení je věcí interpretace, která ovšem pro naše účely nesplňuje nezbytný požadavek formalizovatelnosti. Spolu s tímto promluvovým typem bylo nezbytné zjednodušit i další sémanticko-modální narativní
|
|
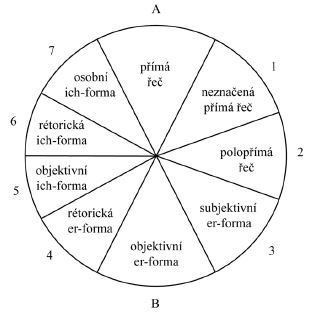
Obr. 2 Doleželovo schematické zobrazení promluv ve fikčních narativech. Schéma jsme doplnili písmeny a číslicemi po obvodu kruhu. |
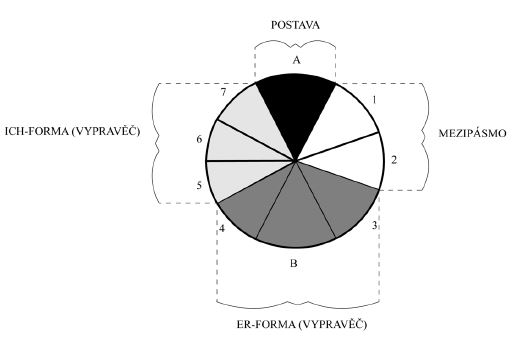
Obr. 3 Úprava (redukce) Doleželova zobrazení pro účely korpusového vymezení promluv ve fikčních narativech. Smysl této redukce není naratologický (!), ale vyplývá z potřeby formalizovaného zpracování autorského korpusu, včetně všech jeho segmentů.
kategorie, kterých Doležel užívá. Konkrétně se jedná o veškeré modální realizace narativní ich-formy a er-formy. Situaci lze přehledně zobrazit ve schématu. První schéma (obr. 2) je převzato ze jmenované Doleželovy publikace,[13] zatímco druhé (obr. 3) je redukcí, kterou jsme provedli pro potřeby maximálně formalizované analýzy narativního diskursu.
Ze schématu je zřejmé, že uvedená redukce nezasahuje do Doleželovy taxonomie, pouze ji pro potřeby interního tagování narativního diskursu zjednodušuje do oblastí, které svými rysy umožní relativně formalizované vymezení. Tuto transformaci jsme provedli na základě formálně-typologických shod v jednotlivých pásmech, mezi kterými platí vztahy vyjádřené v tabulce 6.
Ve výsledku tedy dostaneme speciálně označkovaný korpus fikčních narativů, v němž bude každý subkorpus (povídkový soubor) dále segmentován na oblast er-formy, ich-formy, polopřímé řeči, neznačené přímé řeči a přímé řeči, jinými slovy na segment vypravěče, mezipásma a segment postavy. Tabulka 7 uvádí tagy, které budou použity při segmentaci textu na základě popsaného postupu.
Tyto tři základní oblasti promluvových úseků ve fikčním narativu vyplývají z Doleželovy metodologie, která jednotlivé promluvy interpretuje jako míru inkorporace distinktivních rysů subjektivity a objektivity. Typ subjektivní er-formy je výsledkem takovéto inkorporace, tj. formální realizace subjektivního modu
| typ | |
| A ≠ B | přímá řeč |
| objektivní er-forma | |
| A ∩ B = {xi ∈ A ∧ xi ¬ ∈ B} | neznačená přímá řeč |
| polopřímá řeč | |
| 3 ~ B ~ 4 | objektivní er-forma |
| subjektivní er-forma | |
| rétorická er-forma | |
| 5 ~ 6 ~ 7 | osobní ich-forma |
| rétorická ich-forma | |
| objektivní ich-forma |
Tab. 6 Formální vztahy mezi jednotlivými promluvovými typy vyjádřené pomocí základních matematických symbolů. Typy promluv A a B vyjadřují v Doleželově taxonomii základní opozici. Promluvy 1 a 2 jsou dány na základě pronikání rysů A a B, kdy ovšem žádný z těchto rysů se nenachází současně v A i v B, což neplatí pro promluvový typ 4 (smíšenou řeč). Vztahy mezi promluvovými typy B, 3, 4 a 5, 6, 7 jsou vyjádřením přibližnosti, kterou zakládá jejich formální aspekt. Modálně-sémanticky se však jedná o rozdílné vyprávěcí promluvy.
Pozn.: xi = jeden z příznaků, xii = dva z příznaků, xiii = tři z příznaků
| < nazev_souboru > | název textového souboru, např. Čep_01 |
| < nazev_dila > | např. Dvojí domov |
| < prvni_vydani > | např. 1926 |
| < excerpce > | excerpované vydání, např. 1969 |
| < text > < /text > | začátek/konec textu |
| < kap > < /kap > | začátek/konec kapitoly |
| < n > < /n > | začátek/konec názvu kapitoly |
| < ich > | ich-forma |
| < er > | er-forma |
| < ppr > | polopřímá řeč |
| < npr > | neznačená přímá řeč |
| < pr > | přímá řeč |
Tab. 7 Vyznačení tagů pro identifikaci jednotlivých textů, jejich částí a promluvových úseků
v narativním rámci er-formy. Splývání hranic mezi objektivní narativní promluvou a subjektivní promluvou Doležel vysvětluje pojmem neutralizace, která dosahuje nejvyšších hodnot u smíšené řeči, jež je narativní promluvou subjektivní er-formy. Z toho, co bylo právě uvedeno, vyplývá, že na základě takto navržené segmentace korpusu (v tuto chvíli máme na mysli nejnižší úroveň promluvových pásem) bude možné sledovat proměny mezi těmito dílčími subkategoriemi
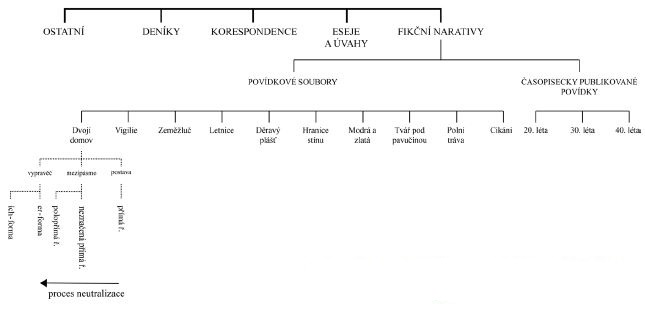
Obr. 4 Kompletní struktura Slovníku Jana Čepa s naznačenými oblastmi promluvových typů
(vypravěč, mezipásmo, postava) a případně sledovat procesy neutralizace apod.[14] Rovněž bude možné vyvozovat tvrzení o modalitách jednotlivých promluvových typů na základě příznakové distribuce a frekvence lexikálních jednotek v daném pásmu (např. povaha er-formy, přímých řečí apod.). Získané hodnoty lze použít i pro srovnávání z hlediska chronologie (např. vývojové proměny vyprávěcí er-formy atd.).
Snahou korpusového zpracování Čepova díla je především přispět k analýze narativního fikčního diskursu takovým způsobem, aby vlastní literárněvědné analýze a interpretaci poskytlo již předem systematicky a analyticky roztříděný materiál, který by bylo možné podrobit dalšímu zkoumání, jež by se primárně soustředilo na literárněvědnou oblast bádání. Na základě autorského korpusu je například možné systematizovat poznatky o narativní situaci, typech vypravěčů či narativních pásmech. Systém formální analýzy bude založen na součinnosti kvantitativní a korpusové metody, jež se bude týkat typologicky rozdílných jazykových segmentů (lemma, tvar, kolokace, n-gramy, věty apod.).
Speciálně navržený autorský slovník by mohl zprostředkovat některé základní systémové informace týkající se lexikální oblasti ve fikčních narativech Jana Čepa. Ve výsledku bude možné srovnávat hodnoty nejen mezi izolovanými lexikálními jednotkami, ale sledovat a „poměřovat“ i jejich kontexty, a to z hlediska jak kvalitativního (typ lexikálního souvýskytu), tak kvantitativního (frekvence
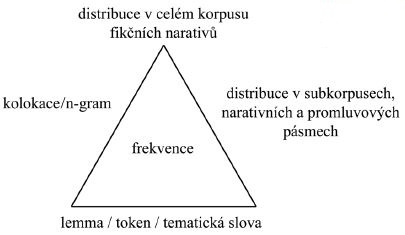
Obr. 5 Systém základního funkčního propojení jednotlivých kategorií ve Slovníku Jana Čepa
souvýskytu). Korpusová a lexikostatistická analýza ovšem nemůže plnohodnotně nahradit literárněvědnou analýzu. Kvantitativní analýza autorského jazyka je tak pouze předstupněm k analýze samostatné, což platí jak v lingvistice, tak v literární vědě. Korpus pro ni ale poskytuje kvantitativní data. V této souvislosti je nicméně nezbytné konstatovat, že uvedená jemná klasifikace promluvových pásem fikčních narativů má rovněž svá nezanedbatelná úskalí. Jejich problematičnost vyplývá zejména ze složitých sémantických modifikací promluvových úseků v moderních fikčních narativech. Ze sémantického hlediska jsou hranice jednotlivých promluvových typů či narativních modů mnohdy neostré a nejednoznačné. Na řadě míst je proto třeba před samotným označením (tagováním) příslušného typu provést důkladnou a věcnou narativní analýzu, v níž nejproblematičtější (z hlediska našeho návrhu) bude nepochybně polopřímá řeč. Tento aspekt je současně nejdiskutabilnějším místem představené koncepce daného korpusu a vyžaduje důkladnější prověření formou testování.
6 Závěrem
V roce 1987 M. Těšitelová ve své studii vyjmenovala řadu disciplín a oborů (pedagogiku, lékařské vědy, sociologii apod.), které využívají výsledků lingvistické kvantitativní metodologie. S postupným rozvojem analytických možností v rámci této oblasti výzkumu, které přinášejí zejména moderní korpusové nástroje, se přirozeně posunují i hranice jejich využití. Na příkladu modelu slovníku Jana Čepa jsme se pokusili navrhnout strategii propojení kvantitativní a korpusové analýzy s literárněvědnou oblastí. Do jaké míry bude možné realizovat veškeré cíle a zda se výchozí předpoklady potvrdí, ukáže teprve reálné testování poté, co budou ukončeny základní práce na vybudování korpusu fikčních narativů.[15] Přesto je možné očekávat, že pomocí současných korpusových nástrojů, které [129]umožňují systematické třídění a statistickou klasifikaci různých vrstev a oblastí jazykové a textové materie, lze literárněvědnou analýzu prohloubit a zpřesnit například tím, že její závěry bude možno porovnávat s výsledky kvantitativně-korpusové analýzy daného textu v širším kontextu jeho díla. Současně by však bylo velkým nedorozuměním, pokud by se statistické a korpusové metody užívaly na úkor jiných literárněvědných metod. Korpus a jeho nástroje nemohou nahradit komplexní literárněvědnou analýzu a interpretaci. Je ovšem možné ji částečně a významně podpořit objektivizovanou kvantitativní analýzou uměleckého jazyka prováděnou na účelově koncipovaném autorském korpusu. Na některé z jevů, které mohou uniknout pozornosti literárního interpreta, by bylo možné upozornit korpusovou a kvantitativní systematizací, v rámci které může být zajímavé sledovat, jak se například proměňují jednotlivé narativní a promluvové kategorie v rámci celého díla (lineární hledisko) i z hlediska vývojových překryvů (synchronie), jak je to naznačeno ve schématu v obrázku 1.
Závěrem lze konstatovat, že navržená jemná segmentace nemusí představovat jedinou možnost. Jiný model by mohl být založen na mapování oblastí deskripce a narace apod. Na obecnější rovině nás tyto úvahy vedou k zamyšlení nad možností realizovat větší korpusy, které by sloužily jak potřebám literárních historiků a teoretiků, tak lingvistům.[16] Větší databáze textů by například mohla poskytnout informace o historicky se proměňujících narativních kategoriích, tématech ve spojení s lingvistickými otázkami apod. V neposlední řadě se nabízí využít korpusových technik v textologii či v intertextuálním bádání, při určování autorství a jinde.
LITERATURA
BENSE, M. (1962): Theorie der Texte: Eine Einführung in neuere Auffassungen und Methoden. Köln – Berlin: Kiepenheuer & Witsch Verlag.
BENSE, M. (1967): Teorie textů. Praha: Odeon.
CVRČEK, V. – KOVÁŘÍKOVÁ, D. (2011): Možnosti a meze korpusové lingvistiky. Naše řeč, 94, s. 113–133.
CVRČEK, V. (2006): Metoda zjišťování kolokační platnosti frekventovaných bigramů pomocí ranku. In: F. Čermák – M. Šulc (eds.), Kolokace. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 36–55.
ČERMÁK, F. – CVRČEK, V. (2008): Slovník Bohumila Hrabala. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK.
ČERMÁK, F. (1995): Jazykový korpus: prostředek a zdroj poznání. Slovo a slovesnost, 56, s. 119–140.
[130]ČERMÁK, F. (2006): Kolokace v lingvistice. In: F. Čermák – M. Šulc (eds.), Kolokace. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 9–16.
ČERMÁK, F. (2006): Korpusová lingvistika dnešní doby. In: F. Čermák – R. Blatná (eds.), Korpusová lingvistika: Stav a modelové přístupy. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 9–18.
ČERMÁK, F. (2006): Statistické metody hledání frazémů a idiomů v korpusech. In: F. Čermák – M. Šulc (eds.), Kolokace. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 94–106.
ČERMÁK, F. (2007): Slovník Karla Čapka. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK.
ČERMÁKOVÁ, A. Kolokace a valence některých případů substantiv. In: F. Čermák – M. Šulc (eds.), Kolokace. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 107–141.
DAVIDOVÁ GLOGAROVÁ, J. – ČECH, R. (2013): Tematická koncentrace textu – některé aspekty autorského stylu Ladislava Jehličky. Naše řeč, 96, s. 234–245.
DILL, CH. (1959): Lexika zu einzelnen Schriftstellern. Forschung und Fortschritte, 33, s. 340–346.
DOLEŽEL, L. (1965): Pražská škola a statistická teorie básnického jazyka. Česká literatura, 13, s. 101–113.
DOLEŽEL, L. (1993): Narativní způsoby v české literatuře. Praha: Československý spisovatel.
HAASOVÁ, L. (1999): Pokus o stanovení sémantických tříd v díle Jaroslava Seiferta. In: Varia 8. Bratislava: Slovenská jazykovedná spoločnosť pri SAV, s. 75–81.
HAJIČOVÁ, E. (2006): Využití korpusu pro ověřování lingvistických hypotéz. In: F. Čermák – R. Blatná (eds.), Korpusová lingvistika: Stav a modelové přístupy. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 118–130.
HOLMAN, P. (1988): Frekvenční slovník básnického díla Otokara Březiny. Naše řeč, 71, s. 41–49.
HOLMAN, P. (1993): Frequenzwörterbuch zum lyrischen Werk von Otokar Brezina. Bausteine zur slavischen Philologie und Kulturgeschichte N. F. Reihe A, Slavistische Forschungen. Köln – Weimar – Wien: Böhlau.
JANOVEC, L. (1998): Využití programu Concorder pro tvorbu autorských slovníků. In: Varia 7. Bratislava: Slovenská jazykovedná spoločnosť pri SAV, s. 63–69.
JANOVEC, L. (1999): Z autorského slovníku Jaroslava Seiferta – sémantická charakteristika a použití zájmena ‚já‘ a ‚my‘ v některých sbírkách. In: Varia 8. Bratislava: Slovenská jazykovedná spoločnosť pri SAV, s. 82–90.
JANOVEC, L. (2003): Autorský slovník Jaroslava Seiferta – současný stav, změny koncepce a budoucnost projektu. In: Varia 10. Bratislava: Slovenská jazykovedná spoločnosť pri SAV, s. 197–202.
JELÍNEK, J. – BEČKA, J. V. – TĚŠITELOVÁ, M. (1961): Frekvence slov, slovních druhů a tvarů v českém jazyce. Praha: Státní pedagogické nakladatelství.
KLIVAR, M. (1984): Význam kvantitativní lingvistiky pro literární teorii. In: Literárněvědný sborník Památníku národního písemnictví. Praha: Památník národního písemnictví.
KONEČNÁ, D. (1960): Ke zkoumání češtiny z hlediska strojového překladu. Naše řeč, 43, s. 156–163.
KONEČNÁ, D. (1960): První pokus se strojovým překladem v Československu. Naše řeč, 43, s. 109–111.
[131]KOPŘIVOVÁ, M. (2006): Kolokační profil nejčastějších adjektiv v korpusech ČNK. In: F. Čermák – R. Blatná (eds.), Korpusová lingvistika: Stav a modelové přístupy. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 180–204.
KRÁLÍK, J. (2006): Zamyšlení nad velkými výběry. In: F. Čermák – R. Blatná (eds.), Korpusová lingvistika: Stav a modelové přístupy. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 205–209.
KRÁLÍK, O. (1961): Autorské slovníky. In: Slovo a slovesnost, 22, s. 239–240.
KŘEN, M. (2006): Kolokační míry a čeština: srovnání na datech ČNK. In: F. Čermák – M. Šulc (eds.), Kolokace. Praha: Nakladatelství Lidové noviny – Ústav Českého národního korpusu FF UK, s. 223–248.
LUTTERER, I. (1965): O jedné z cest moderní jazykovědy. Naše řeč, 48, s. 234–238.
MACHOVÁ, S. (1997): Autorský slovník básnického díla Jaroslava Seiferta. In: Filologické studie 20. Praha: Karolinum, s. 29–34.
POŘÍZKA, P. – SCHÄFFER, F. (2010): Svět jako vědomí a nic Ladislava Klímy v olomouckém korpusu české esejistiky přelomu 19. a 20. století. In: Věčnost není děravá kapsa, aby se z ní něco ztratilo. Soubor studií věnovaných Ladislavu Klímovi. Olomouc: Univerzita Palackého.
ŠTINDLOVÁ, J. (1961): Využití technických prostředků mechanizace a automatizace při organizaci archivních sbírek odborného názvosloví. Naše řeč, 44, s. 23–32.
ŠTINDLOVÁ, J. (1969): Konkordanční a frekvenční index k Slezským písním Petra Bezruče. Praha – Ostrava: Socialistická akademie v Ostravě – Ústav pro jazyk český ČSAV.
TĚŠITELOVÁ, M. (1948): Frekvence slov a tvarů ve spise Život a dílo skladatele Foltýna od Karla Čapka. Naše řeč, 32, s. 126–130.
TĚŠITELOVÁ, M. (1955): Poznámky k slovní zásobě v románu Karla Čapka Život a dílo skladatele Foltýna. Naše řeč, 38, s. 297–307.
TĚŠITELOVÁ, M. (1968): O básnickém jazyce z hlediska statistického. Slovo a slovesnost, 29, s. 362–368.
TĚŠITELOVÁ, M. (1974): Otázky lexikální statistiky. Praha: Academia.
TĚŠITELOVÁ, M. (1987): O využití výsledků kvantitativní lingvistiky. Naše řeč, 70, s. 225–236.
TĚŠITELOVÁ, M. (2000): K současné české próze z hlediska frekvence slov. Naše řeč, 83, s. 1–9.
TRÁVNÍČEK, M. (1996): Pouť a vyhnanství: život a dílo Jana Čepa. Brno: Proglas.
PRAMENY (pouze první knižní vydání povídkových souborů)
ČEP, J. (1926): Dvojí domov. Praha: Ladislav Kuncíř.
ČEP, J. (1928): Vigilie. Praha: Rudolf Škeřík.
ČEP, J. (1931): Zeměžluč. Praha: Melantrich.
ČEP, J. (1932): Letnice. Praha: Melantrich.
ČEP, J. (1934): Děravý plášť. Praha: Melantrich.
ČEP, J. (1935): Hranice stínu. Praha: Melantrich.
ČEP, J. (1938): Modrá a zlatá. Praha: Melantrich.
ČEP, J. (1941): Tvář pod pavučinou. Praha: Vyšehrad.
ČEP, J. (1946): Polní tráva. Brno: Svobodné noviny.
ČEP, J. (1953): Cikáni. Mnichov: Sdružení československých politických uprchlíků v Německu.
[1] Článek vznikl za podpory grantu ESF Inovace bohemistických studií v mezioborových kontextech (CZ.1.07/2.2.00/28.0178).
[2] Jedná se o rozložení SYN2010. Informace přebíráme ze stránek ČNK: < http://ucnk.ff.cuni.cz/syn2010.php >.
[3] Machová konstatuje, že s výjimkou „počítačového popisu jazyka básnického díla Vítězslava Nezvala, který započal koncem 60. let na Filozofické fakultě brněnské univerzity anglista a teoretik překladu Jiří Levý a který byl předčasně ukončen jeho smrtí“, projekt autorského slovníku dosud realizován nebyl a že se realizovaly „pouze frekvenční slovníky jednotlivých děl některých autorů […] nebo frekvenční slovníky vytvořené z náhodně vybraných vzorků textů daného autora“ (Machová, 1997, s. 31). Kromě toho Machová uvádí, že na PedF UK se od 2. poloviny 90. let 20. stol. připravuje Index slov a tvarů v rukopisech staročeské kroniky tak řečeného Dalimila (tamtéž, s. 32); viz také Janovec (2003, s. 64–65). K dalším pracím obou autorů viz bibliografie.
[4] Autoři publikace Frekvence slov, slovních druhů a tvarů v českém jazyce z roku 1961 odkazují k řadě zahraničních i českých prací, které lingvistickou statistiku využily jako hlavní metodu (Jelínek – Bečka – Těšitelová, 1961, s. 11–18). K historii kvantitativního výzkumu srov. též studie Konečné (1960), Štindlové (1961), Lutterera (1965), Doležela (1965) aj.
[5] Benseho kniha byla přeložena do češtiny a vydána pod názvem Teorie textů v roce 1967.
[6] Konkrétně rozlišuje substantivní slovní skupinu, kterou vedle substantiv tvoří adjektiva a předložky, skupinu verbální, kterou tvoří slovesa, příslovce a spojky (viz Těšitelová, 1968, s. 363n.). V rámci těchto úvah, které reflektují statistické poměry mezi slovními druhy, je dnes díky moderním korpusovým nástrojům rovněž možné statisticky sledovat slovní druhy v jejich syntaktické platnosti, což Těšitelová nezohledňuje.
[7] Fikční povaha textu zde vyjadřuje její anti-mimetickou a ryze literárně-uměleckou relevanci, nikoli nepravdivost.
[8] V případě jmenovaných zdrojů komplikuje komparaci skutečnost, že žádný z nich není s korpusem Čepových textů časově synchronní. Tyto okolnosti je třeba mít na paměti. V případě materiálu, který je součástí publikace Frekvence slov, slovních druhů a tvarů (konkrétně část A – umělecké texty), se sice jedná o díla, která jsou časově synchronní s pozdější Čepovou tvorbou, avšak na druhé straně zde máme k dispozici „pouze“ frekvenční, nikoli korpusové údaje.
[9] V roce 1948 Čep natrvalo emigroval z Československa. Žil ve Francii, působil mimo jiné v rozhlase Svobodná Evropa, kde měl svůj pravidelný pořad o nových knižních publikacích a kultuře. V tomto období převládá esejistická tvorba.
[10] Rekonstrukce této části Čepovy tvorby se opírala o informace získané z Trávníčkových poznatků, z Čepovy bibliografie sestavené Tomášem Kubíčkem (publikována bude v Kubíčkově připravované monografii o J. Čepovi) a z dalšího archivního hledání.
[11] Tohoto pojmu užíváme proto, že z textologického hlediska je vývoj jednotlivých povídkových knih samozřejmě složitější, než jak nám jej dokáže modelovat čistě formální schéma. Například do vývoje souborů Dvojí domov a Vigilie zasáhla kromě aktuálního dobového a autorského kontextu i ta skutečnost, že v redukované podobě byly publikovány opakovaně jako součást knihy Zeměžluč (viz tabulka 3). Vývojové aspekty lze navíc postihovat různými textologickými metodami.
[12] Celkovou rekonstrukci jsme provedli pomocí zde jmenovaných literárněvědných zdrojů (viz pozn. 10). Opírali jsme se zejména o Trávníčkovu monografii (Trávníček, 1996). Zde Trávníček uvádí, že např. soubor Zeměžluč, který poprvé vyšel v roce 1931, vznikal od roku 1928, kdy Čep publikoval povídky Starcův smích a Hoře z lásky; v případě souboru Cikáni, který vyšel po Čepově emigraci, první vydání z roku 1953 doplňujeme ve shodě s M. Trávníčkem o dva texty – Květnové dni a Tři pocestní, které původně nebyly součástí povídkového souboru. Trávníček toto vřazení vysvětluje velice blízkými analogiemi v tvůrčím procesu, které obě povídky sbližují s celou knihou.
[13] Do schématu jsme připojili obvodové číselné údaje (1–7) a písmena (A, B), které nejsou součástí původního Doleželova zobrazení.
[14] Tato redukce nesmí být chápána z naratologického hlediska, ale jako funkční modifikace pro potřeby kvantitativní a korpusové formalizace. Účelově zrušené stupně sémantických modalit v narativních pásmech vyplynou z korpusových a kvantitativních informací. Tak bude možné sledovat, zda například v pásmu er-formy vlivem kumulace signifikantních jazykových (lexikálních) prvků a jejich kontextů (kolokací, n-gramů) dochází k inklinaci k subjektivizovanému modu vyprávěcí er-formy apod.
[15] Aktuálně je k dispozici necelých 50 % korpusu fikčních narativů. Korpus dosud nebyl kompletně tagován.
[16] Na ÚČL AV ČR je v současnosti řešen projekt korpusového zpracování české poezie 19. a počátku 20. století. Projekt je zajímavý tím, že se soustředí na versologické kategorie. V případě prozaických textů relevantní korpus dosud postrádáme.
Katedra bohemistiky FF UP
Křížkovského 10, 771 80 Olomouc
richard.zmelik@gmail.com
Naše řeč, ročník 97 (2014), číslo 3, s. 113-131
Předchozí Z dopisů redakci
Následující Barbora Kukrechtová: Rodinná korespondence Karla Havlíčka v českých překladech
© 2011 – HTML 4.01 – CSS 2.1