
Tematická koncentrace textu – některé aspekty autorského stylu Ladislava Jehličky
Jana Davidová Glogarová, Radek Čech
[Články]
Thematic concentration of a text – some aspects of Ladislav Jehlička’s authorial style
Analysis of thematic concentration is a method for the detection of thematic words and quantification of thematic concentration in a text. This method was applied to articles by the Czech Catholic writer and journalist Ladislav Jehlička from the period 1936–1942. The aim was to compare two sets of texts: texts that are considered by literary theorists to be ‘problematic’ due to their expression of extreme right-wing views, and texts that are ‘neutral’, dealing only with general social questions. We expect that, in view of the choice of theme, the ‘problematic’ texts will be more influenced by the author’s ideological stance, which in turn will be reflected in the linguistic characteristics of the texts. We then compare texts published under Jehlička’s real name with those which appeared under the pseudonym ‘Eljen’. The results reveal a surprisingly small presence of words expressing a right-wing stance or ‘problematic’ themes (e.g., fascism, Jewish) among so called thematic words as well as an independence of the thematic concentration of ideology. Finally, a non-significant difference between Jehlička’s and Eljen’s texts can be viewed as a proof of the author’s relatively stable style.
Key words: anti-Semitism, Fascism, ideology, journalism, Ladislav Jehlička, nationalism, Nazism, quantitative linguistic analysis, thematic concentration of the text
Klíčová slova: antisemitismus, fašismus, ideologie, publicistika, Ladislav Jehlička, nacionalismus, nacismus, kvantitativní lingvistická analýza, tematická koncentrace textu
[1]1 Úvod
Ladislav Jehlička (1916–1996), český katolický publicista, vstoupil do kulturního života ve druhé polovině třicátých let 20. století. Po boku osobností, jako byl Jaroslav Durych, Jan Čep či Jan Zahradníček, publikoval své články na stránkách katolických kulturních revue Akord, Jitro, Řád a Obnova. Jehličkova raná publicistika, zaměřená k politické tematice, se vyznačovala radikálním katolicismem a nacionalismem. Literárními historiky jsou připomínány rovněž jeho sympatie k fašismu a nacismu či sklony k antisemitismu (Kautman, 2011, s. 534; Med, 2010, s. 286; Putna, 2010, s. 708; Stankovič, 2000, s. 544). V hodnocení [235]Jehličkovy celoživotní tvorby dodnes převažuje toto hledisko, a to i přes skutečnost, že v pozdějších letech své kontroverzní názory ze třicátých let v mnohém přehodnotil a profiloval se spíše jako protikomunisticky zaměřený publicista (Jehlička, 2010).
Je třeba zdůraznit, že každá tradiční literárněhistorická interpretace je z principu založena na subjektivním vnímání autorova textu. Tento přístup má jistě nesporné výhody – dovoluje relativně komplexní vhled do dané problematiky, umožňuje využít badateli jeho zkušenosti či talent, nabízí možnost určitého nadhledu, osobní invence atd. Na druhou stranu je literárněhistorická interpretace vždy ovlivněna dobovým kontextem, osobními, politickými, uměleckými preferencemi, světonázorem či předsudky interpretátora apod. Alternativou k interpretačním metodám jsou metody experimentální, jejichž výhodou je zejména to, že výrazně redukují právě vliv subjektivismu. Negativní stránkou těchto tzv. intersubjektivních metod je především silný redukcionismus – provádíme-li experiment, jsme nuceni významný počet faktorů zanedbat, aby byl experiment vůbec realizovatelný.
Vzhledem k tomu, že používání experimentálního přístupu je v literární historii velmi neobvyklé, pokusili jsme se pro analýzu části publicistické tvorby Ladislava Jehličky (viz oddíl 3) použít jednu z kvantitativnělingvistických metod, a to metodu měření tzv. tematické koncentrace (dále TK) textu (srov. Popescu et al., 2009). Ve vybraných textech jsme konkrétně sledovali:
a) na jaká témata se Ladislav Jehlička ve své publicistické tvorbě zaměřuje a jak silnou roli v jeho textech hrají témata fašismu, antisemitismu, nacismu atd.;
b) zda se liší (vzhledem k hodnotám TK) charakter textů obsahujících tato „problematická“ témata od textů „neutrálních“, tj. zaměřených na otázky společenského dění, kulturního života, školství, mladých lidí či role katolicismu ve společnosti apod. Předpokládáme přitom, že „problematické“ texty budou vzhledem k volbě tématu více ovlivněny ideologickým postojem autora a že budou mít persvazivnější charakter, což by se mělo projevit i na povaze jazyka, který autor použil (srov. Čech, 2013; Fairlough, 1998; Salama, 2011; Stubbs, 1994);
c) rozdíly TK pro ověření Jehličkova autorského pseudonymu – Ladislav Jehlička ve třicátých letech publikoval některé ze svých článků pod pseudonymem Eljen. Přestože existují nepřímé doklady této skutečnosti, např. podobný autorský styl, stejná tematika či autorské odkazy mezi jednotlivými články, jednoznačný doklad toho, že texty podepsané tímto pseudonymem napsal skutečně Jehlička, dodnes chybí. Předpokládáme tedy, že mezi skupinami textů, které jsou podepsány Ladislav Jehlička, a těmi, které byly publikovány pod pseudonymem Eljen, se projeví pouze nesignifikantní rozdíl v hodnotách TK. Je třeba zdůraznit, že testování tohoto předpokladu není více než sondou do problematiky autorství, protože není možné stanovit autorství na základě jediné vlastnosti textu (srov. Grieve, 2007). Na druhou stranu bylo při analýze projevů československých
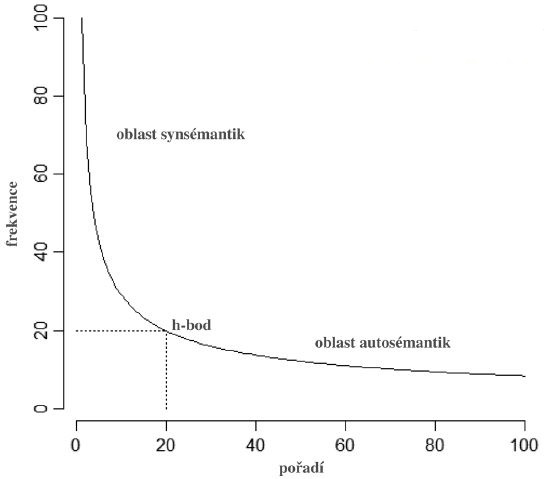
Obr. 1 Ukázka grafického znázornění h-bodu v hypotetické distribuci slov.
a českých prezidentů ukázano (srov. Čech, 2013), že mezi projevy jednotlivých prezidentů existují signifikantní rozdíly v hodnotách TK, přestože se jedná o velice úzce vymezený žánr, a že tedy autorství (v případě prezidentů je definováno jako projev politické odpovědnosti za přednesený text) má vliv na TK textu. Jinými slovy, případný signifikantní rozdíl TK mezi texty podepsanými Jehličkovým jménem a texty podepsanými pseudonymem Eljen je třeba brát jako impuls k hlubší analýze autorských charakteristik obou skupin textů. Naopak nesignifikantní rozdíl může být považován za jeden z projevů relativně stabilního autorského stylu.
Chceme zdůraznit, že následující analýza by měla být vnímána především jako jedna z pilotních studií (srov. Glogarová – David – Čech, 2013), jejichž cílem je mimo jiné prozkoumat, zda vůbec a do jaké míry je možné metodu měření TK v literárněhistorické práci použít.
2 Metoda měření tematické koncentrace textu
Metoda měření tematické koncentrace textu je založena na analýze frekvenční struktury textu – vychází z vlastnosti tzv. h-bodu a z frekvenčních charakteristik jazykových jednotek (např. slov či lemmat) vyskytujících se nad tímto bodem (srov. Popescu, 2007; Popescu et al., 2009; Popescu – Altmann, 2011). Zmíněný [237]h-bod vypočítáme následujícím způsobem: seřadíme-li slova (případně lemmata) daného textu podle frekvence v sestupném pořadí, pak hodnota h-bodu je určena místem, kde se pořadí slova rovná jeho frekvenci, tj.
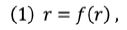
kde r je pořadí slova a f(r) frekvence slova v daném pořadí. Pokud se ve frekvenční distribuci žádná taková hodnota nevyskytuje, pak se h-bod vypočítá podle vzorce (2),
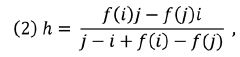
kde i a j jsou pořadí slov a f(i) a f(j) jsou jejich frekvence, přičemž i < j, kde i je největší takové číslo, pro které i < f(i), a j je nejmenší takové číslo, pro které j > f(j). Z lingvistického hlediska je h-bod důležitý proto, že je možné jej ve frekvenční distribuci slov daného textu interpretovat jako neostrou hranici mezi synsémantickými a autosémantickými slovy (srov. Popescu, 2007; Popescu et al., 2009) – slova nad h-bodem jsou většinou slova synsémantická a slova pod ním slova autosémantická, srov. obr. 1.
Přítomnost autosémantických slov v oblasti synsémantik pak můžeme považovat za jistý druh anomálie, která je odrazem specifické vlastnosti zkoumaného textu, konkrétně určité „zaměřenosti“ (či „koncentrovanosti“) autora na téma či témata, reprezentované právě autosémantiky (či jinak vymezenými tzv. tematickými slovy, viz níže) nacházejícími se v oblasti synsémantik. Vzhledem k tomu, že h-bod lze chápat jako tzv. pevný bod ve frekvenční charakteristice textu, je možné jej použít jako východisko pro kvantifikaci tematické váhy slova (či lemmatu) a výpočtu TK celého textu.
Při stanovení tematické váhy jednotlivých slov (či lemmat) se vychází jednak z frekvence sledovaných jazykových jednotek, jednak z jejich pořadí. Vyjdeme-li z předpokladu, že TK textu je reprezentována tematickými slovy[2] nad h-bodem (označme pořadí těchto slov symbolem r’), je možné tematickou váhu slova charakterizovat jako vzdálenost mezi h-bodem a pořadím slova r’, kterou vynásobíme jeho frekvencí f(r’), tj.
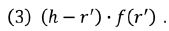
Čím je tedy pořadí r’ slova nižší (a čím je vyšší i jeho frekvence f(r’)), tím je jeho tematická váha větší. Následně tematické váhy normalizujeme – normalizace je nutným krokem, který umožňuje eliminovat vliv délky textu, díky čemuž [238]lze porovnávat hodnoty TK u textů různého rozsahu. V našem případě (ve shodě s Popescem et al., 2009) normalizujeme tak, že tematickou váhu každého slova vydělíme sumou rozdílu vzdáleností (h – r) u všech slov nad h-bodem a nejvyšší frekvencí slova v textu f(1). Samozřejmě by bylo možné tematické váhy normalizovat i jinými způsoby (např. sumou rozdílu vzdáleností (h – r) u všech slov nad h-bodem a jejich frekvence), ale zvolený způsob normalizace se ukázal být (alespoň v našem případě) dostatečným prostředkem eliminace vlivu délky textu (viz část 3 a obr. 2), proto setrváváme u tohoto postupu. Konkrétně tedy sumu všech rozdílů vzdálenosti vypočítáme
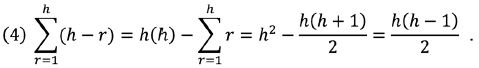
Vydělíme-li tematickou váhu slova (3) touto sumou (4), vynásobenou nejvyšší frekvencí slova v textu f(1), můžeme stanovit index tematické váhy slova TV jako
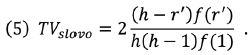
TK celého textu je pak dána součtem hodnot tematických vah jednotlivých tematických slov nad h-bodem, tj.
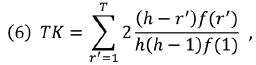
kde T je počet tematických slov nad h-bodem.
Pro ilustraci představíme celý postup na Jehličkově článku Mládí a poezie. V tabulce 1 je 12 nejfrekventovanějších lemmat tohoto textu.
| Pořadí | lemma | frekvence | Tab. 1 Frekvence lemmat v článku Ladislava Jehličky Mládí a poezie, tučně označená lemmata reprezentují tematická slova. |
| 1 | být | 57 | |
| 2 | a | 53 | |
| 3 | v | 24 | |
| 4 | se | 21 | |
| 5 | ale | 15 | |
| 6 | k | 15 | |
| 7 | člověk | 13 | |
| 8 | on | 13 | |
| 9 | že | 12 | |
| 10 | hrdinství | 11 | |
| 11 | tento | 10 | |
| 12 | ten | 10 |
[239]Vzhledem k tomu, že v tabulce 1 se u žádného lemmatu pořadí nerovná frekvenci, r ≠ f(r), použijeme vzorec (2) a získáváme
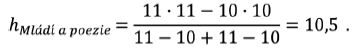
Sledujeme-li slova v tabulce 1, vidíme, že se nad h-bodem vyskytují dvě tematická slova: člověk a hrdinství. Tematickou váhu slova člověk vypočítáme na základě vzorce (5), tj.
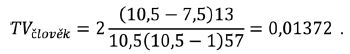
Vzhledem k tomu, že v tabulce 1 jsou dvě slova s frekvencí f = 13, přičemž se jedná o sedmé a osmé slovo v pořadí, je hodnota r’ dána průměrem pořadí slov se stejnou frekvencí, tj. r’člověk = (7 + 8) / 2 = 7,5. Analogicky vypočítáme i tematickou váhu slova hrdinství a podle vzorce (6) můžeme stanovit TK celého textu, tj.
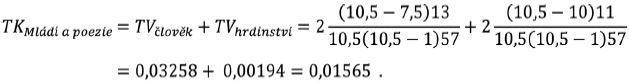
Takto postupujeme u všech textů. Zjištěné rozdíly hodnot mezi jednotlivými texty, případně skupinami textů, je možné statisticky testovat (viz následující část).
3 Jazykový materiál a metoda testování rozdílů hodnot tematické koncentrace
Jazykový materiál použitý pro naši studii představuje soubor publicistických textů Ladislava Jehličky z let 1936–1942, lemmatizovaný dle metodologie použité v Pražském závislostním korpusu 2.0 (Hajič et al., 2006). Z tohoto souboru jsme vybrali skupinu dvaceti osmi textů, které jsme následně záměrně rozdělili do dvou skupin. Do první skupiny jsme zařadili články, které jsou literární historií považovány za problematické vzhledem k tématům, o nichž pojednávaly, například otázce nacionalismu a fašismu. Druhou skupinu tvoří texty, které z hlediska zastoupení těchto témat můžeme považovat za neutrální (srov. Prameny). V jednotlivých textech byla detekována tematická slova, vypočítána jejich tematická váha a následně určena hodnota TK celého textu (srov. tab. 2).
| TK | N | Problematické | TK | N | |
| Svatý Václav a Praha | 0,027098 | 434 | Víra a chléb | 0,007143 | 520 |
| Z kulturní periferie | 0,046992 | 498 | Fráze a politika | 0 | 537 |
| Dluh dosud nesplacený | 0,06677 | 503 | Na dlouhé lokte | 0 | 599 |
| Slavné dny světového sbratření | 0 | 581 | Němci a my | 0 | 602 |
| Katolictví tvořitelem nové Evropy | 0,089778 | 583 | Vystrkují růžky | 0 | 611 |
| Katolictví tvořitelem nového světa | 0,020915 | 649 | Tajemství propagandy | 0,083333 | 671 |
| Novákova Praha barokní | 0 | 681 | Laická morálka | 0,008065 | 678 |
| O katolických studentech i pro ně | 0 | 692 | Dvojí kolej v politice | 0,006405 | 698 |
| Veni sancte | 0,0414 | 845 | Staří manifestují – mladí do práce | 0,005291 | 762 |
| Mládí a poezie | 0,015653 | 904 | Národ na šikmé ploše | 0 | 787 |
| Šaldův odkaz | 0 | 939 | Zúčtování s minulostí cestou do budoucna | 0 | 902 |
| Durychův příklad | 0 | 971 | Budou se ubíjet mladí lidé? | 0 | 976 |
| Vnitropolitické poměry ve Francii | 0,072516 | 978 | Proč jsme přáteli nového Španělska | 0,015556 | 1306 |
| Dr. Josef Pekař | 0,021227 | 1134 | Světlo z Německa | 0,030381 | 2176 |
Tab. 2 Tematická koncentrace TK jednotlivých textů a jejich délka N.
Nakonec jsme pro každou skupinu článků vypočítali průměrnou hodnotu TK a rozdíl hodnot jsme testovali prostřednictvím asymptotického z-testu[3], tj.
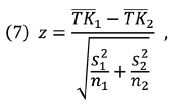
kde TK je průměrná hodnota TK dané skupiny textů, s je rozptyl a n je počet měření v dané skupině. Rozdíl mezi dvěma průměry je považován za signifikantní, pokud je vypočítaná hodnota z vyšší než 1,96 (hladina významnosti α = 0,05).
Je dobře známo, že mnohé kvantitativní charakteristiky textu (za všechny uveďme jen type-token ratio či indexy slovního bohatství), jsou závislé na jeho délce, tudíž rozdíly mezi těmito vlastnostmi neodrážejí vliv např. autorství, žánru, období či zvoleného tématu, ale jsou především projevem rozdílných délek textů. Proto jsme se rozhodli nejdříve sledovat, zda hodnoty TK v našem vzorku jsou,
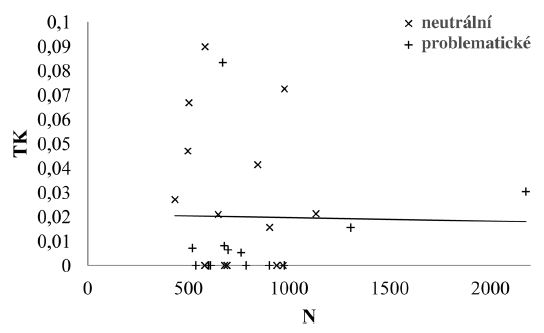
Obr. 2 Vztah mezi délkou textů N a hodnotami tematické koncentrace TK u 28 Jehličkových textů, viz tab. 2.
či nejsou na délce textu závislé. Na první pohled by se snad mohlo zdát, že TK na délce textu „přirozeně“ závislá být musí – s rostoucí délkou textu roste hodnota h-bodu a s ní i pravděpodobnost, že se nad h-bodem objeví autosémantická slova. Ovšem díky tomu, že významným faktorem určujícím tematickou váhu slov je jejich frekvence a vzdálenost od h-bodu a že je TK koncentrace normalizována (viz výše), je vliv délky textu eliminován. V námi analyzovaných textech délka textu na hodnoty TK vliv nemá, evidentní je relativně velký rozptyl hodnot, viz obr. 2.
4 Výsledky
Prostřednictvím výše popsané metody jsme v každém textu nejdříve detekovali tematická lemmata nad h-bodem (viz tabulka 3). V žádném ze zkoumaných článků překvapivě nefiguruje lemma vyjadřující autorovu inklinaci k fašismu, nacismu či antisemitismu jako lemma tematické.[4] Vyvstává tak otázka, zda v Jehličkově publicistice ze třicátých let opravdu hrají tak stěžejní roli, jak je to tradičně interpretováno literární historií.
| problematické texty | |||
| lemma | TV | lemma | TV |
| člověk | 0,08533 | propaganda | 0,08333 |
| národní | 0,05435 | Guardini | 0,01282 |
| doba | 0,04699 | Itálie | 0,01131 |
| strana | 0,04123 | život | 0,01006 |
| dítě | 0,03606 | morálka | 0,00806 |
| francouzský | 0,02664 | Německo | 0,00751 |
| český | 0,02098 | nový | 0,00714 |
| lidský | 0,02092 | strana | 0,00641 |
| Pekař | 0,01850 | mladý | 0,00529 |
| člověk | 0,01372 | Španělsko | 0,00424 |
| dílo | 0,01242 |
|
|
| Praha | 0,00612 |
|
|
| škola | 0,00534 |
|
|
| Francie | 0,00465 |
|
|
| život | 0,00444 |
|
|
| český | 0,00273 |
|
|
| hrdinství | 0,00193 |
|
|
Tab. 3 Tematická lemmata a jejich tematická váha v jednotlivých publicistických textech Ladislava Jehličky. Lemmata jsou uspořádána sestupně vzhledem k jejich tematické váze. Lemmata člověk a český jsou v tabulce uvedena dvakrát, což znamená, že se jako tematická slova nad h-bodem vyskytla ve dvou různých textech.
K dalšímu překvapivému zjištění vedlo porovnání průměrných TK „problematických“ a „neutrálních“ textů, které ukázalo, že průměrná TK „problematických“ textů je téměř třikrát nižší než u textů „neutrálních“ (viz tabulka 4).
|
| průměrná TK v jednom textu | s2 |
| problematické texty | 0,01116 | 0,000504023 |
| neproblematické texty | 0,02874 | 0,000923327 |
Tab. 4 Průměrná TK problematických a neproblematických textů Ladislava Jehličky.
Testujeme-li však rozdíly TK pomocí vzorce (7), dostáváme
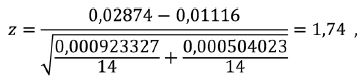
tedy nesignifikantní rozdíl (hladina významnosti α = 0,05), což znamená, že se obě skupiny textů vzhledem k TK významně neliší.
[243]Porovnání TK článků, které jsou podepsány autorovým plným jménem, s těmi podepsanými pseudonymem Eljen, přineslo výsledky prezentované v tabulce 5.
|
| průměrná TK v jednom textu | s2 |
| Eljen | 0,02872 | 0,001260498 |
| Jehlička | 0,02525 | 0,001205268 |
Tab. 5 Průměrná TK textů podepsaných pseudonymem Eljen a plným jménem Ladislav Jehlička.
Mezi průměrnými hodnotami TK u textů v tabulce 5 není signifikantní rozdíl, což můžeme brát jako jeden z projevů stabilního autorského stylu, srov.
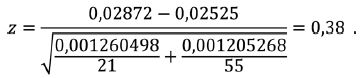
5 Závěr
Výsledky analýzy TK ukázaly, že „problematická“ či ideologicky zatížená témata, např. fašismus, antisemitismus, nejsou v uvedených článcích reprezentována tematickými slovy (viz tabulka 3). Dále se nepotvrdil náš předpoklad, že „problematické“ texty by vzhledem k volbě tématu měly být více ovlivněny ideologickým postojem autora, což by se mělo projevit i v rozdílných charakteristikách jejich TK. Vzhledem k tomu, že se však problematická témata v textech neprojevila prostřednictvím tematických slov, nezodpovězena zůstává otázka, jak silnou roli v publicistice Ladislava Jehličky hrají. Analýza naopak potvrdila konzistentnost autorského stylu Ladislava Jehličky vzhledem k tematické koncentraci. Ta se odráží také v nesignifikantních rozdílech mezi skupinou textů, které autor publikoval pod svým plným jménem, a články podepsanými pseudonymem Eljen.
Jsme si vědomi skutečnosti, že kromě již zmíněného redukcionismu přináší metoda analýzy tematické koncentrace textu další úskalí. Dodnes nebyla přesvědčivě prokázána relevantnost její aplikace na literární či publicistická díla, která jsou založena na autorské snaze o osobitý styl, na pečlivé volbě slov, využívání synonym či obrazných pojmenování. Vyvstává proto otázka, nakolik metoda tematické analýzy textu dokáže zmíněné aspekty reflektovat.
Výsledky, které jsme analýzou získali, nás rozhodně nevedou k přesvědčení o nevhodnosti tradičních literárněhistorických metod, ani ke zpochybnění toho, jak je na základě těchto metod hodnocena publicistika Ladislava Jehličky. Na druhou stranu se domníváme, že experimentální přístupy mohou být i pro literární historii inspirativní.
[244]LITERATURA
ČECH, R. (2013): Language and ideology: Quantitative thematic analysis of New Year speeches given by Czechoslovak and Czech presidents (1949–2011). Quality & Quantity. [přijato k otištění]
DAVIDOVÁ GLOGAROVÁ, J. (2011): Místo Ladislava Jehličky v české katolické publicistice ve 30. letech 20. století. In: E. Prihodová (ed.), Kontexty a inšpirácie katolíckej moderny. Ružomberok: Verbum – vydavateľstvo KU, s. 66–89.
DAVIDOVÁ GLOGAROVÁ, J. – DAVID, J. – ČECH, R. (2013): Analýza tematické koncentrace textu: komparace publicistiky Ladislava Jehličky a Karla Čapka. Slovo a slovesnost, 74, s. 41–54.
FAIRCLOUGH, N. (1989): Language and Power. London: Longman.
GRIEVE, J. W. (2007): Quantitative authorship attribution: an evaluation of techniques. Literary and Linguistic Computing, 22, s. 251–270.
JEHLIČKA, L. (2010): Křik koruny svatováclavské. Praha: Torst.
KAUTMAN, F. (2011): Láďa Jehla. Několik črt k lidskému profilu Ladislava Jehličky. In: L. Jehlička, Křik koruny svatováclavské. Praha: Torst, s. 533–535.
MED, J. (2010): Literární život ve stínu Mnichova (1938–1939). Praha: Academia.
PUTNA, M. C. (2010): Česká katolická literatura v kontextech 1918–1945. Praha: Torst.
POPESCU, I. (2007): Text ranking by the weight of highly frequent words. In: P. Grzybek – R. Köhler (eds.), Exact methods in the study of language and text. Berlin – New York: Mounton de Gruyter, s. 557–567.
POPESCU, I. – ALTMANN, G. – GRZYBEK, P. – JAYARAM, D. B. – KÖHLER, R. – KRUPA, V. – MAČUTEK, J. – PUSTET, R. – UHLÍŘOVÁ, L. – VIDYA, N. M. (2009): Word frequency studies. Berlin – New York: Mouton de Gruyter.
POPESCU, I. – ALTMANN, G. (2011): Thematic concentration in texts. In: E. Kelih et al. (eds.), Issues in Quantitative Linguistics. Lüdenscheid: RAM, s. 110–116.
SALAMA, A. H. Y. (2011): Ideological collocation and the recontexualization of Wahhabi-Saudi Islam post-9/11: A synergy of corpus linguistics and critical discourse analysis. Discourse & Society, 22, s. 315–342.
STANKOVIČ, A. (2000): Bořitel moderních českých historických a politických mýtů. In: M. Drápala (ed.), Na ztracené vartě západu. Antologie české nesocialistické publicistiky z let 1945–1948. Praha: Prostor, s. 473–480.
STANKOVIČ, A. (2010): Odešel veselý zpátečník. In: L. Jehlička, Křik koruny svatováclavské. Praha: Torst, s. 536–539.
STUBBS, M. (1994): Grammar, Text, and Ideology: Computer-assisted Methods in the Linguistics of Representation. Applied Linguistics, 15, s. 201–223.
PRAMENY
Neutrální
JEHLIČKA, L. (1940): Dluh dosud nesplacený. Obnova, 16, s. 5.
JEHLIČKA, L. (1936–1937): Dr. Josef Pekař. Jitro, 7, s. 199–201.
JEHLIČKA, L. (1936–1937): Durychův příklad. K jeho padesátinám. Jitro, 2, s. 102–103.
JEHLIČKA, L. (1937): Katolictví tvořitelem nové Evropy. Obnova, 10, s. 6.
[245]JEHLIČKA, L. (1937): Katolictví tvořitelem nového světa. Obnova, 5, s. 2.
JEHLIČKA, L. (1938): Novákova Praha barokní. Obnova, 30, s. 6.
JEHLIČKA, L. (1936–1937): Mládí a poezie. Jitro, 3, s. 65–66.
JEHLIČKA, L. (1938): O katolických studentech i pro ně. Obnova, 26, s. 3.
JEHLIČKA, L. (1938): Slavné dny světového sbratření. Obnova, 23, s. 5.
JEHLIČKA, L. (1939): Svatý Václav a Praha. Obnova, 39, s. 5.
JEHLIČKA, L. (1936–1937): Šaldův odkaz. Jitro, 9, s. 260–261.
JEHLIČKA, L. (1937): Veni sancte. Obnova, 27, s. 1–2.
JEHLIČKA, L. (1937): Vnitropolitické poměry ve Francii. Obnova, 24, s. 3.
JEHLIČKA, L. (1938): Z kulturní periferie. Obnova, 20, s. 6.
Problematické
JEHLIČKA, L. (1938): Budou se ubíjet mladí lidé? Obnova, 42, s. 1–2.
JEHLIČKA, L. (1939): Dvojí kolej v politice. Obnova, 2, s. 2.
JEHLIČKA, L. (1938): Fráze a politika. Obnova, 19, s. 4.
JEHLIČKA, L. (1937): Laická morálka. Obnova, 9, s. 7.
JEHLIČKA, L. (1938): Na dlouhé lokte. Obnova, 45, s. 1.
JEHLIČKA, L. (1939): Národ na šikmé ploše. Obnova, 1, s. 1–2.
JEHLIČKA, L. (1939): Němci a my. Obnova, 7, s. 1.
JEHLIČKA, L. (1937): Proč jsme přáteli nového Španělska. Obnova, 37, s. 2–3.
JEHLIČKA, L. (1938): Staří manifestují, mladí do práce. Obnova, 44, s. 1.
JEHLIČKA, L. (1937): Světlo z Německa. Řád, 6, s. 387–391.
JEHLIČKA, L. (1939): Tajemství propagandy. Obnova, 4, s. 3.
JEHLIČKA, L. (1938): Víra a chléb. Obnova, 47, s. 1.
JEHLIČKA, L. (1940): Vystrkují růžky. Obnova, 4, s. 1.
JEHLIČKA, L. (1938): Zúčtování s minulostí cestou do budoucna. Obnova, 40, s. 2.
[1] Text příspěvku vznikl jako součást řešení grantového úkolu GA ČR č. P406/11/0268 Historická sémantika a projektu SGS Ostravské univerzity v Ostravě č. 9/FF/2011 Literatura v širších kulturních kontextech.
[2] Za tematická slova budeme ve shodě s Popescem et al. (2009) považovat substantiva a jejich predikáty prvního řádu, tj. adjektiva a verba (s výjimkou sloves být, mít, moci, muset, smět).
[3] V kvantitativní lingvistice se tento test většinou označuje jako u-test, což vyjadřuje, že jde o test za předpokladu normality.
[4] Pozornost poutá pouze zastoupení výrazů český a národní, za nimiž můžeme odkrývat Jehličkův nacionalismus, který je literární historií připomínán jako určující rys jeho rané publicistiky. Výrazy však stejně tak můžeme interpretovat ve vztahu k Jehličkově pozornosti věnované problémům české státní existence na sklonku třicátých let. Za zmínku stojí také skutečnost, že analýza tematické koncentrace demokraticky orientované publicistiky Karla Čapka ze stejného období odhalila jako nejsilnější tematické slovo výraz národ (Davidová Glogarová – David – Čech, 2013, s. 49).
Jana Davidová Glogarová
Ústav pro regionální studia FF OU
Reální 5, 701 03 Ostrava
glogarova.jana@seznam.cz
Radek Čech
Katedra českého jazyka FF OU
Reální 5, 701 03 Ostrava
cechradek@gmail.com
Naše řeč, ročník 96 (2013), číslo 5, s. 234-245
Předchozí Ginka Bakărdžieva: Rozhovor s Františkem Danešem
Následující Radek Skarnitzl, Petra Bartošová: Výzkum lingvální artikulace pomocí elektropalatografie na příkladu českých palatálních exploziv
© 2011 – HTML 4.01 – CSS 2.1