
Experimentální zkoumání stylotvorných faktorů: první výstupy
Jan Chromý, Jiří Milička
[Články]
Experimental research on style-forming factors: first outcomes
The paper introduces an experiment on the role of preparedness in writing. The experiment took place in 2010. Participants (N = 51; students of Charles University in Prague) were randomly divided into two groups: group N (N = 24) and group P (N = 27). Their main task was to describe the plot of a short animated film Quest. Group N started to write right after seeing each part of the film, group P had 5 minutes to prepare. Significant differences in the sentence length and number of revisions were shown between the two groups. It is claimed that preparedness is a valid styleforming factor, i.e. it influences both the process and the result of writing. Furthermore, the same method could be used for the analysis of the role of other style-forming factors in the writing process.
Key words: experimental linguistics; preparedness; style-forming factors; writing
Klíčová slova: experimentální lingvistika; připravenost; stylotvorné faktory; psaní
[1]V Naší řeči 2/2012 jsme podrobili kritické analýze koncepci stylotvorných faktorů v československé lingvistice. Došli jsme k tomuto závěru: „Pojetí stylotvorných faktorů bylo sice ve své době světově jedinečné, zároveň se však téměř koncepčně nerozvíjelo. Analyzujeme-li problémy, které jsou s tímto pojetím spojeny, dojdeme k několika zásadním problémům: 1. Nesleduje se procesuální vrstva stylu. 2. Faktory jsou vyvozovány ex-post. 3. Není jasné, na co jednotlivé faktory při produkci textu působí a jakou silou. 4. Některé faktory jsou komplexní a rozložitelné na dílčí faktory. 5. Potenciálním faktorem může být cokoliv.“ (Chromý, 2012, s. 68) Jedno z možných řešení těchto problémů vidíme v experimentálním zkoumání celého stylotvorného procesu. Příkladu, jak takové zkoumání může vypadat, věnujeme tento článek.
V roce 2010 jsme na Filozofické fakultě Univerzity Karlovy v Praze uskutečnili experiment zaměřený na výzkum role stylotvorného faktoru připravenost/nepřipravenost v produkci psaného textu. Tento stylotvorný faktor jsme si vybrali z toho důvodu, že je poměrně snadno operacionalizovatelný (i když jsou s tím spojeny jisté teoreticko-metodologické problémy – viz dále) a že se o něm ve zkoumání psaní dosud moc neuvažovalo (lze říci, že zatímco se rozlišuje připravené a nepřipravené [182]mluvení, spojuje se psaní obvykle pouze s připraveností). Cílem popisovaného výzkumu tedy bylo zjistit, jestli připravenost/nepřipravenost jako stylotvorný faktor má vliv na to, jak vzniká psaný text, a na jeho výslednou podobu.
Účastníci
Experiment proběhl v červnu 2010 a účastnilo se ho 51 osob (studenti bakalářského studia na Filozofické fakultě Univerzity Karlovy v Praze), z toho 7 mužů a 44 žen. Účast byla dobrovolná a každá testovaná osoba za účast obdržela 200 Kč. Testované osoby byly náhodně rozděleny do dvou skupin po 24 (skupina N), resp. 27 lidech (skupina P).
Metoda
Testované osoby měly dva úkoly. První úkol (takzvaný „měsíční test“) se zaměřoval na určení rychlosti psaní na počítači u jednotlivých účastníků výzkumu. Jeho základním principem byla co největší redukce kognitivního úsilí při psaní. Participanti po dobu tří minut museli neustále dokola psát názvy měsíců tak, jak jdou za sebou v kalendáři. Předpokladem bylo, že hodnota získaná tímto způsobem reflektuje pouze „manuální“ schopnosti pisatele. Tímto testem jsme získali možnost srovnávat rychlost psaní jednotlivých testovaných osob v rámci samotného druhého úkolu (viz níže).
Druhá část experimentu spočívala v popisu filmového díla. Použit byl animovaný film Quest (1996, režie Tyron Montgomery, stopáž 11 minut), který byl nejprve testovaným osobám promítnut vcelku, poté po částech (pět částí, každá část odpovídala svébytné pasáži filmu). Po zhlédnutí každé části měly testované osoby za úkol popsat její děj (pokyn zněl „Popište děj filmu tak, aby člověk, který film neviděl, si ho dovedl představit. Nesnažte se o interpretaci či recenzi, popisujte pouze dění jako takové.“). Skupina N popisovala děj každé části ihned po jejím zhlédnutí (tzn. v nepřipraveném modu), skupina P měla nejprve 5 minut na písemnou přípravu (připravený modus). Pro účely přípravy testované osoby ze skupiny P obdržely 5 papírových karet o velikosti A6 a propisku. Na obrazovce jim byl odpočítáván čas. Čas na samotný popis děje do počítače byl pro obě skupiny neomezený (pokyn zněl „Na popis děje po každé části máte neomezeně mnoho času. Pište do té doby, než budete se svým textem zcela spokojeni.“). Po celou dobu psaní měly testované osoby na uších protihluková sluchátka, aby nebyly jakkoliv vyrušovány (zároveň byly instruovány, aby se soustředily výhradně na samotné psaní a nenechávaly se rozptylovat).
Pro účely experimentu byl využíván jednoduchý program vytvořený Jiřím Miličkou, který zaznamenával, jaké klávesy byly stisknuty, čas každého stisku jakékoli klávesy a pozici kurzoru v textu. Na základě výstupů tohoto programu tak bylo možné [183]automaticky spočítat počet oprav, rychlost psaní atd. O existenci programu Inputlog (Leijten – Van Waes, 2006), který bychom jinak jistě využili, jsme v době experimentu nevěděli. Miličkův program však na požadavky, které jsme měli, bez obtíží stačil.
Výsledky
Ve zkoumaných datech jsme si všímali čtyř jevů procesuální vrstvy (rychlosti psaní, tzv. R-burstu, tzv. P-burstu a počtu oprav) a dále čtyř jevů rezultativní vrstvy (délka textu, délka vět, délka slov, type-token ratio). Skóre u každé testované osoby se počítalo na základě souhrnu všech pěti dílčích textů, které daná osoba napsala. Poté bylo spočítáno průměrné skóre všech testovaných osob v rámci daných skupin, následně byl pro porovnání průměrů v daných skupinách použit oboustranný t-test určený pro porovnání průměrů dvou skupin nezávislých měření (Volín, 2007, s. 110). Průměrné hodnoty jsou uváděny se zaokrouhlením na jedno desetinné místo, výsledky t-testu se zaokrouhlením na dvě desetinná místa.
Rychlost psaní byla měřena ve znacích za sekundu, přičemž ve výpočtech jsme – z důvodu možné srovnatelnosti výsledků mezi jedinci – operovali s tzv. relativní rychlostí psaní (rychlost psaní v rámci popisu děje / rychlost zjištěná v měsíčním testu). Průměrná relativní rychlost u nepřipravených projevů byla po zaokrouhlení 0,5, průměrná relativní rychlost u projevů připravených byla rovněž 0,5. T-test zde neukázal signifikantní rozdíl: t (49) = 1,13; p = 0,27.
R-bust je měřítko, které udává průměrný počet úhozů, po nichž následuje oprava (srov. např. Chenoweth – Hayes, 2003). Průměrný R-burst v rámci nepřipravených projevů činil 30,7 úhozu, v rámci připravených projevů 34,9 úhozu. Ani v tomto měřítku T-test neukázal signifikantní rozdíl: t (49) = 0,60; p = 0,55.
P-burst signalizuje průměrný počet úhozů, po nichž následuje pauza určité stanovené velikosti. V tomto výzkumu jsme pracovali s dvěma hodnotami pauz: a) pauzy delší než 1 sekunda, b) pauzy delší než 2 sekundy. V případě pauz delších než 1 sekunda byl průměrný P-burst v nepřipravených projevech 18,6 úhozu, v rámci připravených projevů 17,5 úhozu. V případě pauz delších než 2 sekundy byl průměrný P-burst u skupiny N 39 úhozů, u skupiny P 36,3 úhozu. Ani v jednom případě T-test neukázal signifikantní rozdíl. V případě pauz delších než 1 sekunda: t (49) = 0,67; p = 0,51, v případě dvousekundových a delších pauz: t (49) = 0,84; p = 0,4.
Jiná byla situace u počtu oprav (počet smazaných znaků v rámci daného textu). V nepřipravených projevech byl průměrný počet oprav 467,2 zn., zatímco v projevech připravených průměrný počet oprav činil 289,6 zn. T-test ukázal signifikantní rozdíl: t (49) = 2,29; p < 0,05. Připravené projevy se tedy v procesuální vrstvě výrazně odlišovaly od nepřipravených co do revizí psaného textu.
V návaznosti na to jsme se podívali ještě na průměrnou délku oprav ve znacích. V nepřipravených projevech byla průměrná délka opravy 3,7 zn., v připravených 3,1 zn. T-test signifikantní rozdíl neukázal: t (49) = 1,56; p = 0,13.
[184]Co se týče jevů rezultativní vrstvy stylu, délka textu a délka slov se signifikantně nelišily. V nepřipravených projevech byla průměrná délka textu 3486,1 písmene a průměrná délka slova 4,7 písmene, v projevech připravených byla průměrná délka textu 3017,8 písmene a průměrná délka slova 4,6 písmene. T-test signifikantní rozdíly neukázal. V rámci délky textu platilo t (49) = 1,39; p = 0,17, pro délku slov t (49) = 0,35; p = 0,73.
Při měření lexikální rozrůzněnosti se signifikantní rozdíl opět neukázal. Prvních 100 tokenů obsahovalo u připravených textů průměrně 79,3 typu, u nepřipravených textů byl průměr 77,2 typu, t (49) = 1,27; p = 0,21. Prvních 200 tokenů obsahovalo u připravených textů průměrně 142,3 typu, u nepřipravených textů byl průměr 139,9 typů, t (49) = 0,66; p = 0,51. Podobně bychom mohli pokračovat dál, ovšem výsledky by zkreslovalo, že texty některých zkoumaných osob souhrnné délky 300 tokenů nedosahovaly. Pokud všechny připravené texty spojíme do jednoho celku a totéž provedeme s texty nepřipravenými, type-token relation bude mít pro oba celky podobný průběh, což ilustrujeme grafem 1.
Signifikantní rozdíl se naopak ukázal u délky věty. V nepřipravených projevech byla průměrná délka věty 13,2 slova, v projevech připravených průměr činil 10,6 slova. T-test ukázal tyto výsledky: t (49) = 3,09; p < 0,005. Jinými slovy, délka věty byla nejsignifikantnějším rozdílem mezi připravenými a nepřipravenými projevy.
Diskuse
V uvedeném experimentu se ukázaly zajímavé rozdíly mezi připravenou a nepřipravenou psanou produkcí, a to jak procesuálně (v počtu oprav), tak rezultativně (v délce vět). V jiných měřených jevech (délka slov, délka textu, rychlost psaní, P-burst, R-burst, type-token ratio) se rozdíly neprojevily.
První nalezený rozdíl, vyšší počet oprav v nepřipravených projevech, podle našeho názoru reflektuje principiální odlišnost připravených a nepřipravených projevů. Testované osoby v připraveném modu si nejprve vytvoří koncept textu, který posléze přenesou do počítače a upravují jej již jen v dílčích aspektech. Oproti tomu v nepřipraveném modu vytváří testované osoby celý text bezprostředně, což s sebou pochopitelně nese četné revize.
Velmi zajímavý je signifikantní rozdíl mezi oběma mody v délce věty. Délku věty ve slovech lze totiž považovat za ukazatel syntaktické komplexity (jde dokonce o jeden z nejběžnějších a nejspolehlivějších způsobů operacionalizace tohoto jevu – srov. Szmrecsányi, 2004). Platí, že čím více slov věta obsahuje, tím je syntakticky komplexnější. V našem experimentu překvapivě vyšlo, že syntakticky komplexnější věty jsou v nepřipravených projevech, nikoli v projevech připravených. Tento výsledek v tuto chvíli interpretujeme tak, že věty připravených projevů mají sevřenější formu, což by souviselo s předpokládanou vyšší elaborovaností textu těchto projevů. Syntaktická komplexita totiž nemusí nutně korelovat se syntaktickou hustotou (např.
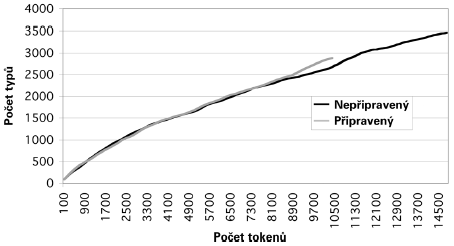
Graf 1 Optické srovnání grafu závislosti počtu typů na počtu tokenů kolekce všech připravených textů s grafem téže závislosti kolekce všech nepřipravených textů.
věta Franta a Pepa o prázdninách přečetli Čapka, Halase, Kunderu a Bezruče. je z hlediska počtu slov syntakticky stejně komplexní jako věta Halas, jenž byl čten málo, méně než Čapek, byl přečten Frantou., na první pohled je však syntakticky „řidší“).
Celkově se tak ukazuje, že faktor připravenosti (tak, jak byl v našem výzkumu operacionalizován) je faktor reálný, který skutečně ovlivňuje některé jevy v produkci psaného textu. Prezentované výsledky jsou však samozřejmě pouze dílčí a je potřeba je ještě rozvinout a podpořit navazujícími analýzami.
Z hlediska zkoumání oprav je například na místě rozdělit jednotlivé opravy do různých skupin podle typu a porovnat zastoupení jednotlivých typů v připravených a nepřipravených projevech (např. opravy překlepů, které lze očekávat přibližně ve stejném zastoupení v připravených i nepřipravených projevech, vs. opravy kompozičního charakteru, které by hypoteticky měly v nepřipravených projevech výrazně převažovat).
V rámci syntaktické komplexity je vhodné přihlédnout k detailnějším měřítkům, než je prostá délka věty ve slovech (rozlišení a oskórování různých větných členů a větných vztahů atd.). Dále je třeba nivelizovat idiosynkratické rozdíly tím, že budou stejní lidé znovu podrobeni zkoumání, avšak s odlišným zadáním (tedy – ti, kteří v prvním experimentu vytvářeli připravený projev, budou psát projev nepřipravený a naopak).
Užitečné by mohlo být zkoumat i další jevy – např. individuální strategie psaní, rozdíly mezi přípravami a výsledným textem u připravených projevů, vztah syntaktické komplexity a propoziční hustoty u připravených a nepřipravených textů, časové rozložení pauz a revizí (např. můžeme předpokládat, že v připravených projevech se pauzy a revize budou více objevovat až v pozdějších fázích psaní) atd.
[186]Na závěr podotýkáme, že při interpretaci našich výsledků bychom měli být opatrní. V prvé řadě je nutné zdůraznit, že připravenost/nepřipravenost je zde určitým způsobem operacionalizována (absencí/přítomností pětiminutové doby na přípravu k následnému psaní do počítače). Námi zvolená operacionalizace je do jisté míry arbitrární a byla by mohla být jiná. To znamená, že naše výsledky se dají vztáhnout pouze k tomuto typu pojetí připravenosti a nikoli k pojetí odlišnému.
Zadruhé je třeba zohledňovat roli samotné úlohy, což je proměnná, jejíž vliv v rámci našeho samotného experimentu nebylo možno posoudit. Je možné, že by se výsledky vlivu připravenosti/nepřipravenosti lišily, kdyby bylo působení tohoto stylotvorného faktoru sledováno na jiném typu úlohy (např. psaní eseje na určité téma apod.).
Zatřetí musíme uvážit, pro jakou populaci je náš vzorek reprezentativní. Jedná se o vysokoškolské studenty humanitních oborů, kteří jsou zvyklí každodenně psát na počítači (v měsíčním testu jen málokdo psal pomaleji než tempem 3 zn./s). Získané výsledky tak rozhodně nelze zobecňovat na celou populaci ČR atp.
Závěr
V tomto textu jsme se snažili ukázat metodu experimentálního zkoumání stylotvorných faktorů. Došli jsme k tomu, že připravenost/nepřipravenost (tak, jak byl námi tento faktor operacionalizován) skutečně ovlivňuje produkci psaného textu, a byli jsme schopni identifikovat konkrétní aspekty psaní, v nichž se tento vliv uplatňuje. Domníváme se, že jsme prokázali, že je tato výzkumná metoda užitečná a že může dosavadní koncepci stylotvorných faktorů významně obohatit.
LITERATURA
CHENOWETH, A. – HAYES, J. (2003): The inner voice in writing. Written communication, 20, s. 99–118.
CHROMÝ, J. (2012): Koncepce stylotvorných faktorů v československé lingvistice: rozbor, kritika, nástin řešení. Naše řeč, 95, s. 57–69.
LEIJTEN, M. – VAN WAES, L. (2006): Inputlog: New perspectives on the logging of on-line writing processes in a Windows environment. In: Computer keystroke logging: Methods and applications. Oxford: Elsevier, s. 73–93.
SZMRECSÁNYI, B. (2004): On operationalizing syntactic complexity. In: Le poids des mots. Lovaň: Presses universitaires de Louvain, s. 1031–1039.
VOLÍN, J. (2007): Statistické metody ve fonetickém výzkumu. Praha: Epocha.
[1] Koncepci experimentu vymyslel, sběr dat organizoval a výsledky interpretoval Jan Chromý, koncepci konzultoval, software pro sběr dat a jejich zpracování vytvořil a statistické výpočty měl na starosti Jiří Milička. Za významnou spolupráci a ochotu při sběru dat děkujeme Jakubu Jehličkovi.
Jan Chromý
Ústav českého jazyka a teorie komunikace FF UK
nám. Jana Palacha 2, 116 38 Praha 1
jan.chromy@ff.cuni.cz
Jiří Milička
Ústav srovnávací jazykovědy FF UK
Celetná 20, 116 42 Praha 1
milicka@centrum.cz
Naše řeč, ročník 95 (2012), číslo 4, s. 181-186
Předchozí Martin Beneš: Psaní velkých písmen v tzv. druhové složce pojmenování
Následující Václav Lábus: Atyp v cihle aneb O jednom progresivním způsobu neologizace
© 2011 – HTML 4.01 – CSS 2.1