
O co se zajímají ti, kdo posílají dopisy, faxy a e-maily jazykové poradně?
Ludmila Uhlířová
[Články]
-
[1]Snadná, pohodlná komunikace pomocí elektronické pošty nebo faxu s sebou přináší podstatné rozšíření písemné agendy jazykové poradny Ústavu pro jazyk český. Zatímco například za celý rok 1995 obdržela jazyková poradna 83 dopisů (v nichž bylo položeno 126 dotazů) a 7 faxů (v nichž bylo položeno 9 dotazů), o dva roky později, v roce 1997, to bylo již 112 dopisů (se 191 dotazy) a 24 faxy (s 31 dotazy), za rok 1998 to bylo 141 dopisů (s 203 dotazy) a 36 faxů (s 64 dotazy). V r. 1999 bylo v období od 1. ledna do 26. dubna 49 dopisů, obsahujících celkem 68 dotazů, a 11 faxů, obsahujících celkem 16 dotazů. Navíc přibylo k uvedenému datu 92 elektronických odpovědí, v nichž bylo zodpovězeno 121 dotazů; to souvisí jednak s připojením Ústavu pro jazyk český na internet, jednak se zahájením experimentálního provozu jazykové poradny na internetu. Rovněž počet telefonických dotazů v posledním období výrazně stoupá. Během čtyř hodin, kdy je v činnosti speciální poradenská telefonní linka, zodpovědí pracovníci několik desítek, někdy až kolem stovky dotazů – jde tedy v pravém slova smyslu o „horkou“ linku, která je po uvedené čtyři hodiny v provozu skutečně nepřetržitě.
I při takto náročné poradenské činnosti, která je při daném personálním obsazení krajní hranicí možného rozsahu služeb pro veřejnost, dbají pracovníci poradny na to, aby zůstala v plné míře zachována základní role, kterou jazyková poradna má, totiž úloha jazykověvýchovná. Chtějí-li jazykovědci veřejnosti skutečně poradit, musí svou odpověď vysvětlit, doporučit řešení, poskytnout varianty pro vlastní uživatelovo rozhodnutí atd. Snaží se neomezovat své odpovědi na holé „ano“ – „ne“, nebýt pouhou „živou“ jazykovou příručkou či „živou“ encyklopedií, jichž mají dnešní jazykoví uživatelé k dispozici zajisté dostatek. Ze zkušenosti ovšem víme, že odpovědi na mnohé jazykové dotazy by tazatelé snadno nalezli, kdyby nahlédli do běžných příruček „pro školu a veřejnost“. Bohužel někteří nejsou zvyklí používat ani nejzákladnější kodifikační příručky a nevědí například ani o posledním vydání Pravidel českého pravopisu z r. 1993. Jiní tazatelé naopak své otázky uvádějí větami jako „V Pravidlech českého pravopisu /ve slovníku /v mluvnici se píše, že…, ale vysvětlete mi, proč…“ apod. [226]Takové dotazy přirozeně souvisejí s vývojovou dynamikou jazyka a mohou inspirovat i nové kodifikační rozhodnutí ze strany jazykovědců, i když třeba jen v záležitostech okrajových. Jazyková poradna tak plní roli autority v jazykových otázkách, roli nositele určité linie v jazykové výchově a jazykové politice a je veřejností vnímána a ceněna jako významná a potřebná národní kulturní hodnota, hodnota s více než půlstoletou tradicí, jíž by se Ústav právě v dnešní době těžko zříkal.
Jazykovědcům přináší poradenská praxe mnohé podněty pro lingvistické a sociolingvistické bádání o jazyce a jeho uživatelích. Cílem tohoto příspěvku, který je motivován bezprostředními zkušenostmi z jazykové poradny, je ukázat, jak jsou jazykové zájmy a „problémy“ tazatelů jazykové poradny podmíněny jejich profesemi a jak lze v této souvislosti interpretovat pojem profesionálního/aktivního/směrodatného uživatele jazyka.
Empirickým východiskem úvah se staly ty dokumenty jazykové poradny, o nichž máme vedeny soustavné záznamy v jazykověporadenské databázi. Jsou to všechny dopisy, faxy a e-maily došlé do poradny v období od ledna 1992 do ledna 1999 a odpovědi pracovníků poradny na ně. K nim jsme připojili výběrové databázové záznamy o telefonických dotazech (a odpovědích na ně za totéž období), které jsou zajímavé tím, že na ně v okamžiku jejich zodpovídání nebyla po ruce rutinní odpověď (zaznamenávat odpovědi na všechny telefonické dotazy by nebylo ani účelné z odborného hlediska, ba ani technicky proveditelné). Data o četnostech dotazů jsou uspořádána do tabulky č. 1 na s. 228.
Tabulka podává přehled o tom, kdo se na jazykovou poradnu obrací a na co se ptá.[2] V prvním sloupci je uvedeno třídění tazatelů – jednotlivců nebo institucí – do šestnácti skupin. O třídění, jak je v tabulce uvedeno, nebylo definitivně rozhodnuto na samém počátku ukládání dokumentů do databáze, ale postupně se [227]vyvíjelo, zjemňovalo se a modifikovalo (počet tazatelských skupin postupně vzrůstal) tak, aby pokud možno odráželo rozdílné profesní potřeby a zájmy tazatelů při zacházení s jazykem, pokud jsme schopni je z dotazu identifikovat. Navržené třídění není jediné možné a mezi jednotlivými skupinami jsou neostré hranice. Způsob třídění budeme ilustrovat na několika konkrétních příkladech. Například jednotliví učitelé kladou otázky týkající se zcela konkrétních problémů pravopisných (doložen máme např. spor kolegyň o i/y v tvarech posesivních adjektiv – Přijeli Novákovi vs. Pozdravujte Novákovy), dotazy na počet a druh vedlejších vět při rozboru souvětí, na shodu podmětu a přísudku, na příklady nadbytečné negace typu svár – nesvár apod.; zahraniční lektor češtiny si ověřuje správnost tvaru kdybyste (proti *kdyby jste). Naproti tomu obdržíme-li dotaz od školy jakožto instituce (s razítkem školy, na hlavičkovém papíře, většinou s názvem školy v prvním řádku adresy), týká se často velkých a/nebo malých počátečních písmen v oficiálním názvu školy, v adrese školy, dále např. interpunkce v právních dokumentech (v dohodě o provedení práce, v zákoně o placení pojistného aj.), informací o literatuře nebo jsou předmětem dotazů takové jazykové problémy, které mají dosah pro výuku, ev. mimoškolní činnost většího žákovského kolektivu (znění testu pro členy včelařského kroužku, problém v maturitním testu), popř. pro život celé školy (jaký nápis má být na dveřích místnosti pro lektory?).
Stejně tak nejsou nepřekročitelné hranice mezi tématy dotazů (vodorovně v tab. č. 1). Tematicky (obsahově) byly dotazy utříděny do deseti skupin, a to na dotazy z oblasti výslovnosti (01), pravopisu (02), tvoření slov (03), tvarosloví (04), syntaxe (05), slovní zásoby (06), stylistiky (07), textové struktury (08), formální úpravy písemností (09) a zbytkové kategorie (10) ostatních dotazů; třídění bylo připraveno tak, aby ve svém celku pokrývalo hlavní oblasti struktury jazyka a jeho užívání a aby přitom vystihovalo nejdůležitější okruhy tazatelských zájmů. K tomu je třeba poznamenat, že tazatelské zájmy jsou širší než problémy týkající se vlastní „jazykové správnosti“; platí to například o dotazech týkajících se formální úpravy písemných projevů, v nichž se tazatelé někdy dožadují „pravidel“ i tam, kde žádná předepsána nejsou, nebo které jsou obsahem speciální normy pro úpravu písemností. Vývoj stále víc ukazuje, že jazyková kodifikace a norma pro úpravu písemností se překrývají např. v nepsaní mezer u spojovníků aj.
Tazatelské skupiny jsou v tabulce uspořádány sestupně podle celkového počtu dotazů, který je uveden v posledním sloupci tabulky. V jednotlivých políčkách tabulky jsou údaje o tom, jak často tazatelé z jednotlivých tazatelských skupin položili dotazy určitého druhu. Například v daném souboru dokumentů je celkem 259 dotazů od novinářů (redaktorů, korektorů); z nich nejvíce, a to 99, se týkalo pravopisu. Atd.
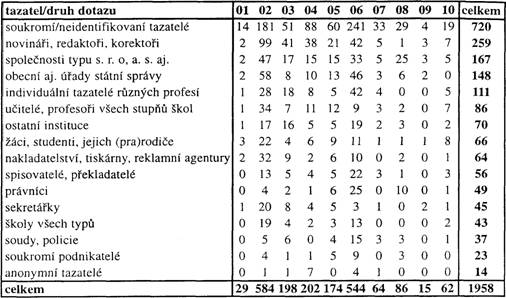
Tab. 1. Četnosti dotazů došlých do jazykové poradny v období od r. 1992 do konce ledna 1999, uspořádané podle tazatelských skupin a témat dotazů
Z dat v tabulce je zřejmé toto:
(1) Různé skupiny tazatelů se obracejí na jazykovou poradnu různě často. Ponecháme-li stranou početnou heterogenní skupinu soukromých/neidentifikovaných tazatelů (tj. těch, v jejichž dopisech je buď výslovně deklarován osobní, „soukromý“ zájem o jazykový problém, anebo těch, u nichž nelze na motivaci dotazu ze znění dopisu jednoznačně usuzovat), pak nejčastější skupinou tazatelů, kteří se obracejí na jazykovou poradnu, jsou – podle očekávání – redaktoři, novináři, korektoři, po nich následují představitelé různých podnikatelských kruhů atd. Anonymní dopisy jsou ojedinělé a jejich obsahem bývají obecné, expresivně laděné stížnosti na „úpadek“ jazyka.
(2) Jazykové zájmy tazatelů jazykové poradny nejsou nikterak rovnoměrné, některá témata, zejména pravopisná a/nebo lexikální, jsou v centru pozornosti jazykových uživatelů, jiná, například výslovnost, jsou spíše periferní – viz poslední řádek tabulky.
Četnosti v posledním řádku tabulky vyjadřují zájmy průměrného tazatele jazykové poradny. Takto kvantifikovaný pojem průměrného tazatele jazykové poradny je pouhou abstrakcí, nicméně abstrakcí sociolingvisticky užitečnou. Její smysl je v tom, že vyjadřuje jedno možné shrnutí a zobecnění jazykových zájmů té části populace, která se zajímá o jazyk aktivně a která svou aktivitu dává najevo tím, že oslovuje jazykovou poradnu. Přitom větší část – téměř dvě třetiny – reprezentuje ty uživatele jazyka, které nazýváme v české lingvistické literatuře směro[229]datnými, profesionálními uživateli, tj. takovými, kteří svým jazykovým chováním a postoji na jazyk působí nejvíce. Jsou to ti uživatelé, kteří nepotřebují znát odpověď na jazykový dotaz jen „pro sebe“ (jako např. luštitel křížovky nebo historik-amatér, který žádá o vysvětlení historických termínů, s nimiž se setkal při četbě historických knih). Jsou to tazatelé, jejichž dotazy nějakým způsobem výslovně souvisejí s jejich rolí v některé veřejné komunikační oblasti, např. s fungováním nějaké instituce či s profesí jednotlivce, a kteří tudíž – a to považujeme za důležité – odpověď (radu, doporučení, poučení, …) jazykové poradny dále šíří v určitém profesním prostředí, např. učitel ve škole, redaktor v novinách, podnikatel v obchodní korespondenci apod., a tím působí na další jazykové uživatele. Nemůžeme se ovšem vyjádřit k otázce, zda takto pojatý průměrný tazatel, definovaný výlučně na základě aktivně projevených zájmových preferencí, je průměrným reprezentantem celé populace českých mluvčích. Odpověď na takovou otázku by vyžadovala rozsáhlejší sociolingvistické šetření.
Porovnáme-li však nyní mezi sebou jednotlivé řádky tab. č. 1 a všimneme-li si četností v jednotlivých políčkách, konstatujeme, že ani jedna tazatelská skupina se nechová – pokud jde o distribuci svých jazykových zájmů – jako skupina „průměrná“. Různé tazatelské skupiny se vzájemně odlišují nejen tím, jak často se obracejí se svými dotazy na jazykovou poradnu, jak o tom byla řeč výše, ale i tím, jaké dotazy o jazyce kladou nejčastěji a jaké naopak zůstávají stranou jejich zájmů. Stručně shrnuto, potvrzuje se dlouholetá empirická zkušenost, že pravopisné dotazy často kladou osoby z těch tazatelských skupin, které primárně zacházejí s psanými texty, tedy ty, které především pociťují ve své každodenní praxi závaznost Pravidel českého pravopisu, eventuálně které by mohly být sankcionovány za pravopisné „chyby“. Jsou to především novináři, redaktoři, editoři, korektoři a nakladatelé, jejichž editační pravopisné prohřešky bývají velmi ostře kritizovány veřejností, dále autoři úředních, administrativních dokumentů různé právní síly, kde je důležité dodržení jednoty pravopisných principů (např. v psaní názvů institucí, při interpunkci apod.), dále sekretářky, a konečně učitelé, kteří učí pravopisu na všech stupních škol a kteří se musejí vyrovnávat s tradičním upřednostněním psané variety jazyka ve školních osnovách. Naproti tomu existují velké tazatelské skupiny s dominantním zájmem o otázky lexikální. Jsou to především skupiny tazatelů, kteří sami texty tvoří, překládají, interpretují, ev. analyzují jejich obsah, tedy spisovatelé, překladatelé, pracovníci právních institucí a policie i specialisté různých profesí v souvislosti s terminologií toho kterého oboru. Potvrzuje se i to, že například učitelé/studenti se více než jiné tazatelské skupiny zajímají o literaturu oboru, o nové slovníky a kodifikační příručky, sekretářky o formální úpravu písemností. Naproti tomu například sekretářky zřídka řeší problémy významu slov. U soudu se neřeší problémy výlučně pravopisné, ale spíše takové, které souvisejí s interpretací textu. Atd.
[230]Pojem „průměrného“ tazatele vymezený kvantitativně na základě distribuce tazatelských priorit se tedy zřetelně rozpadá. Vynecháme-li skupinu soukromých/neidentifikovaných tazatelů, o jejichž profesní či sociální homogennosti se můžeme jen dohadovat, pak se podle tazatelských preferencí, tj. na základě dat v tab. 1, vyčleňují přinejmenším dvě velké množiny tazatelů, a to množina s dominantním zájmem o pravopis, a množina s dominantním zájmem o slovní zásobu. Do první z nich patří novináři, redaktoři, korektoři, obecní, okresní aj. úřady státní správy, společnosti typu s. r. o, a. s. a jiné, školy všech typů, učitelé, profesoři všech stupňů škol, žáci, studenti, jejich rodiče a prarodiče, nakladatelství, tiskárny, reklamní agentury a sekretářky, do druhé patří individuální tazatelé různých (často odborných a vědeckých) profesí, spisovatelé, překladatelé, soukromí podnikatelé, právníci, soudy, policie, různé ostatní instituce (např. knihovny, nemocnice aj.) a konečně ojedinělí anonymní tazatelé (ti poslední většinou kriticky komentují slovotvorné, sémantické a pragmatické aspekty užívání jednoslovného názvu pro Českou republiku). Údaje vybrané z tab. 1 jsou uvedeny v tab. 2 a 3 pro každou z těchto dvou množin zvlášť. V těchto tabulkách jsou tazatelské skupiny opět seřazeny sestupně podle četností jejich dotazů – viz poslední sloupec tabulek. Poslední řádek tabulek sumarizuje četnosti dotazů podle jejich obsahu.
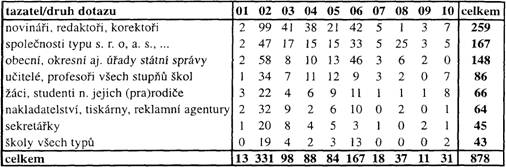
Tab. 2. Tazatelé s největším zájmem o dotazy pravopisné
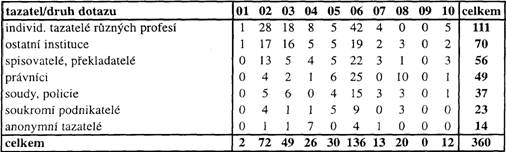
Tab. 3. Tazatelé s největším zájmem o dotazy lexikální
[231]Nabízí se otázka, zda dvojí typ tazatele a – obecněji – dvojí typ profesionálního uživatele jazyka, tak jak se jeví na základě uvedených dat, je pouze specifickou empirickou charakteristikou poradenské databáze, anebo zda databázové údaje jsou jedním konkrétním svědectvím toho, že v české jazykové situaci pravděpodobně nemáme jediný, „obecný“ typ profesionálního uživatele, nýbrž že je jich více, přinejmenším dva.
Pokusíme se v dalším výkladu nalézt argumenty ve prospěch druhé z obou zmíněných alternativ. Za průkazné argumenty budeme považovat to, podaří-li se nalézt obecný pravděpodobnostní model, který by vhodně popisoval empirické rozdělení četností v tab. 1–3, a podaří-li se lingvisticky (resp. sociolingvisticky) zdůvodnit, proč právě daný model je pro daný případ vhodný.
Položme otázku: Obdrží-li jazyková poradna dopis (fax, e-mail), jaká je pravděpodobnost, že příslušného tazatele zajímá problém pravopisný, anebo problém lexikální, anebo problém syntaktický, popř. jiný? Tato otázka má jednak praktický dosah pro provoz jazykové poradny, jednak dosah pro verifikaci sociolingvistického pojmu typu (typů) tazatele (profesionálního uživatele) – o tento druhý aspekt nám jde především. Aspekt prvý, praktický, který lze parafrázovat například otázkou, jaká je pravděpodobnost, že tazatel položí rutinní dotaz a že v dosavadní agendě jazykové poradny bude možno nalézt již hotový vzorec odpovědi – například o psaní velkých písmen v názvech ulic začínajících předložkou – ponecháme nyní stranou. Pro naše účely budeme formulovat výše uvedenou otázku v termínech obvyklých v teorii pravděpodobnosti: Jakým pravděpodobnostním rozdělením se řídí náhodná veličina označující počet vybraných jednotek (= došlých dopisů) vykazujících sledovanou vlastnost (= konkrétní téma dotazu z deseti možných)?
Dříve než se pokusíme hledat takové rozdělení pro každý ze dvou předpokládaných typů profesionálních uživatelů, budeme hledat rozdělení pro data vcelku (tj. pro data v posledním řádku tab. 1).
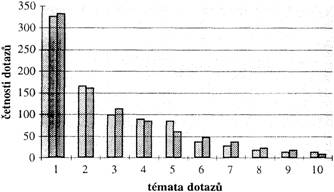
Pro větší názornost jsou na obr. 1 četnosti z posledního řádku tab. 1 uspořádány podle klesajících četností dotazů, tj. první v pořadí je uvedena četnost dotazů pravopisných, druhá v pořadí je četnost dotazů lexikálních atd.
Četnosti dotazů podle témat
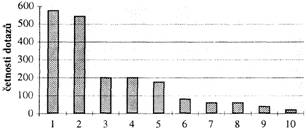
Obr. 1. Témata dotazů podle klesající četnosti (dle tab. 1):
| 1 pravopis | |
| středně četná skupina: | 3 tvarosloví |
| skupina méně četných dotazů: | 6 sémantika textu |
Pro takovéto empirické rozdělení četností se nyní pokusíme nalézt pravděpodobnostní rozdělení, jímž by bylo možno empirická data uspokojivě modelovat. Použijeme k tomu programového vybavení, které je k dispozici pro podobné úlohy, tzv. Altmannova Fitteru (d. cit. v pozn. 1). Fitter umožňuje pohodlnou manipulaci s daty vloženými do počítače. Po vložení vstupních dat (= četnosti v posledním řádku tab. 1) a po spuštění programu dostáváme výsledek: Fitter nenašel žádné přijatelné pravděpodobnostní rozdělení, jímž by bylo možno empirická data modelovat. Jinými slovy, nepodařilo se nalézt žádný pravděpodobnostní model lingvistických zájmů pro jediný typ tazatele. To je výsledek, který jsme vzhledem k heterogennosti dat očekávali.
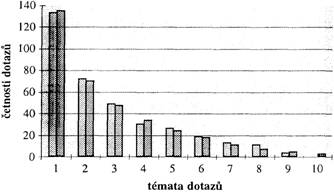
Učiňme nyní další krok. Na základě empirických dat v tab. 2 a 3 vyslovíme hypotézu, že data v tab. 1, pro která se nepodařilo žádný model najít, reprezentují pravděpodobnostní rozdělení složené ze dvou rozdělení, reprezentujících dva různé typy tazatelů. Ověřme tuto hypotézu opět s použitím již citovaného programového vybavení: Budeme testovat, zda lze nalézt model pravděpodobnostního rozdělení odděleně pro data v tab. 2 a data v tab. 3 (vždy v posledním řádku tabulek). Výsledek je tentokrát pozitivní: Vhodným pravděpodobnostním modelem je hypergeometrické rozdělení.
V tab. 4 a 5 jsou uvedeny vedle pořadí Xi a empirických četností Fi (dle posledního řádku v tab. 2, resp. 3) také hodnoty pravděpodobností NPi vypočtené podle vzorce tohoto rozdělení[3]. Shoda empirických a vypočtených hodnot byla ověřena testem χ2 (resp. koeficientem kontingence C pro velké soubory) s přijatelným výsledkem.
| F[i] | NP[i] | |
| 1 | 331 | 333,0888 |
| 2 | 167 | 163,1452 |
| 3 | 98 | 111,5269 |
| 4 | 88 | 82,3135 |
| 5 | 84 | 62,1004 |
| 6 | 37 | 46,6549 |
| 7 | 31 | 34,1484 |
| 8 | 18 | 23,6443 |
| 9 | 13 | 14,6151 |
| 10 | 11 | 6,7626 |
K = 2,5994, M = 0,5470, n = 9, DF = 6, χ2 = 16,3299 P(χ2) = 0,0121
Tab. 4. Model hypergeometrického rozdělení pro tazatele s největším zájmem o dotazy pravopisné
| X[i] | F[i] | NP[i] |
| 1 | 136 | 136,9516 |
| 2 | 72 | 70,7938 |
| 3 | 49 | 48,0438 |
| 4 | 30 | 34,5874 |
| 5 | 26 | 25,1534 |
| 6 | 20 | 18,0103 |
| 7 | 13 | 12,3969 |
| 8 | 12 | 7,9273 |
| 9 | 2 | 4,4001 |
| 10 | 0 | 1,7353 |
K = 3,0211, M = 0,5986, n = 9, DF = 6, χ2 = 6,0691 P(χ2) = 0,4155
Tab. 5. Model hypergeometrického rozdělení pro tazatele s největším zájmem o dotazy lexikální
Na obr. 2 a 3 jsou empirické hodnoty znázorněny vždy v prvním a vypočtené vždy v druhém sloupci z každé dvojice sloupců.
Porovnáme-li obr. 2 a 3, je i z názoru vidět, že rozdělení četností jeví v obou případech velmi podobný průběh, a navíc že tento průběh je nápadně odlišný od toho, který jsme zaznamenali v obr. 1 pro data vcelku.
Obě množiny tazatelů se tedy podařilo – na základě kvantitativní struktury jejich tazatelských zájmů – modelovat pravděpodobnostním rozdělením stejného typu; liší se jen hodnoty parametrů K a M, které určují konkrétní rozdělení náhodné veličiny. Hypergeometrické rozdělení je jedním z nejběžnějších [234]typů pravděpodobnostních rozdělení, kterými lze modelovat náhodné jevy a procesy z různých oblastí života. Pokud jde o jevy jazykové, bylo například prokázáno, že se tímto rozdělením řídí opakování slov v textových blocích.[4] Pro náš případ považujeme za významné to zjištění, že se v rámci sociolingvistického pojmu „průměrného“ tazatele jazykové poradny, tak jak byl vymezen na počátku, podařilo modelovat dvě velké, komplementární skupiny profesionálních tazatelů, které se od sebe liší tím, která jazyková oblast je v centru jejich tazatelských zájmů, ale shodují se v obecné strukturaci svých zájmů, tj. v tom, že se koncentrují vždy právě na jednu určitou zájmovou oblast – ta představuje přibližně polovinu všech jazykových dotazů, které jazykové poradně kladou, zatímco všechny ostatní druhy dotazů představují jejich zájmy vedlejší, až periferní.
Obr. 2
Obr. 3
[235]Model chování profesionálních mluvčích v jejich rolích tazatelů jazykové poradny se tedy podařilo nalézt (připomínáme, že data jsou z dokumentů jazykové poradny za sedmileté období její činnosti, a tedy představují vzorek pro daný účel dostatečně reprezentativní). Dalším krokem je zdůvodnit, proč právě tento pravděpodobnostní model, a ne nějaký jiný, vyhovuje pro daný případ nejlépe. Jinými slovy: Proč je proporcionalita frekvenčních tříd dotazů právě taková, jak byla výše popsána a modelována? Za podstatné pro odpověď na tuto otázku považujeme to, že pravděpodobnost, že tazatel z určité profesní skupiny položí dotaz právě z určité jazykové oblasti (jedné z deseti možných), není při každém jeho dotazu stejná, ale mění se. Je totiž závislá na dotazech, jaké už položil předtím a v nichž se už projevily jeho profesní preference. Pravděpodobnost, že každý další dotaz bude motivován spíše tazatelovým dominantním profesním zájmem, je pak nutně jiná než pravděpodobnost, že bude motivován některým z ostatních jeho zájmů, a s přibývajícími dotazy se mění ve prospěch zájmu dominantního. Právě to je charakteristickým rysem hypergeometrických rozdělení.
Vraťme se nyní ještě jednou k tab. 1. Připomeňme, že četnosti v posledním sloupci této tabulky udávají, jak často se mluvčí z jednotlivých skupin obracejí na jazykovou poradnu. Tyto četnosti považujeme za míru jejich tazatelské aktivity. Zjistili jsme (viz výše), že u jednotlivých skupin se míra tazatelské aktivity liší, a tuto skutečnost jsme komentovali. Poté, co se podařilo nalézt pravděpodobnostní model pro zájmové preference profesionálních mluvčích, se nyní nabízí otázka, zda tento model vyhovuje i jako model jejich tazatelské aktivity. Položme proto otázku analogickou otázce položené výše: Obdrží-li jazyková poradna dopis (fax, e-mail), jaká je pravděpodobnost, že tazatelem bude člověk z určité profesní skupiny (z šestnácti možných)? S použitím stejného softwaru a analogického postupu, který byl popsán výše, zjišťujeme, že tazatelskou aktivitu lze modelovat rovněž pomocí hypergeometrického rozdělení. V tab. 6 a na obr. 4 jsou tazatelské skupiny seřazeny sestupně podle klesajících četností jejich dotazů. V prvním sloupci je uvedeno pořadí skupiny, v druhém empirické četnosti dotazů, v posledním sloupci vypočtené hodnoty hypergeometrického rozdělení. Shoda empirických a vypočtených hodnot byla testována opět testem χ2 s dobrým výsledkem.
Skutečnost, že dva různé aspekty sociolingvistického chování tazatelů jazykové poradny, na jedné straně struktura jejich tazatelských zájmů, na druhé straně míra jejich tazatelské aktivity, mohou být modelovány stejným pravděpodobnostním rozdělením, sama o sobě sice ještě není argumentem pro nějaké definitivní závěry, nicméně dává naději, že popsaným způsobem modelování různých aspektů jazykového chování lze dospět k určitým smysluplným zobecněním empirických poznatků. Přinejmenším se prokázalo, že například pojem směrodatného uživatele jazyka lze pojímat různým způsobem.
| F[i] | NP[i] | |
| 1 | 720 | 717,2030 |
| 2 | 259 | 259,7594 |
| 3 | 167 | 173,6664 |
| 4 | 148 | 133,6264 |
| 5 | 111 | 109,4019 |
| 6 | 86 | 92,6743 |
| 7 | 70 | 80,1405 |
| 8 | 66 | 70,1974 |
| 9 | 64 | 61,9565 |
| 10 | 56 | 54,8724 |
| 11 | 49 | 48,5770 |
| 12 | 45 | 42,7934 |
| 13 | 43 | 37,2776 |
| 14 | 37 | 31,7570 |
| 15 | 23 | 25,8009 |
| 16 | 14 | 18,2959 |
K = 1,7216, M = 0,3706, n = 15, DF = 12, χ2 = 7,1181 P(χ2) = 0,8497
Tab. 6. Pravděpodobnostní model tazatelských aktivit (pomocí hypergeometrického rozdělení)
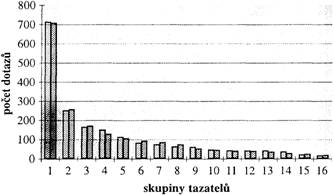
Obr. 4. Pravděpodobnostní model tazatelských aktivit: hodnoty empirické – první sloupec, hodnoty vypočtené – druhý sloupec
[1] Článek vznikl s podporou grantu GA ČR 405/98/0030.
[2] O koncepci databázového zpracování poradenských dokumentů viz L. Uhlířová, Archivace lingvistických dokumentů na počítači I a II, NŘ 79, 1996, s. 171–186, 225–237, L. Uhlířová, Jazyková poradna pro rok 2000, SaS 60, 1999, v tisku. – O dílčích výsledcích zpracování viz L. Uhlířová, „Language Service“ is also a service for linguists, Linguistica Pragensia 1997, s. 82–90. – L. Uhlířová, Linguists vs the Public: An Electronic Database of Letters to the Language Consulting Service as a Source of Sociolinguistic Information, Journal of Quantitative Linguistics, 1998, s. 262–268. – L. Uhlířová, O dialogu mezi jazykovou poradnou a veřejností aneb K čemu slouží počítačová databáze dotazů o jazyce a odpovědí na ně, Česká slavistika 1998, s. 169–177. – I. Svobodová, O psaní velkých písmen, NŘ (v tisku). – I. Svobodová, Poznatky z jazykové poradny jako jedna z možností poznání současného stavu češtiny, Jazykovědné aktuality (v tisku). – A. Černá, Telefonáty v jazykové poradně a jejich databáze, pokus o sociolingvistický pohled, NŘ 82, 1999, s. 237–244. – J. Šimandl, Morfologická problematika a databáze dotazů, NŘ (v tisku). – K výpočtům v celé stati bylo použito Altmannova programového vybavení, viz G. Altmann, Altmann-Fitter. Iterative Anpassung diskreter Wahrscheinlichkeitsverteilungen, RAM-Verlag, Lüdenscheid 1994.
[3] Toto rozdělení má vzorec Px = 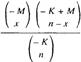 , kde x = 0, 1, 2, …, K>M>0, n ∊ N.
, kde x = 0, 1, 2, …, K>M>0, n ∊ N.
[4] G. Altmann, V. Burdinsky, Towards a law of word repetitions in text-blocks, in: W. Lehfeld – U. Strauss (Eds.), Glottometrika 4, 1982, s. 147–167, Bochum: Brockmeyer.
Naše řeč, ročník 82 (1999), číslo 5, s. 225-236
Předchozí Z dopisů jazykové poradně
Následující Anna Černá: Telefonáty v jazykové poradně a jejich databáze (Pokus o sociolingvistický pohled)
© 2011 – HTML 4.01 – CSS 2.1