
K možnostem korpusového zpracování nadvětných jevů
Lucie Poláková
[Články]
On the possibilities of corpus-based approach to discourse phenomena
The present contribution is a theoretical and methodological study of the possibilities of processing discourse through the use of corpus methods. Despite the description complexity of phenomena “beyond the sentence boundary”, we argue that even more ways of systematic analysis are possible. Taking into account various attempts during the last decade to create discourse-annotated corpora, a reliable way to proceed in any such analysis is shown to be to distinguish between different layers of discourse analysis (in particular between “semantic” and “pragmatic” aspects) and to stick with the linguistic form as opposed to classifying phenomena with no surface realization.
Key words: communication, coreference, corpus annotation, discourse (text), discourse connectives, discourse relations, inference, linguistic methodology, pragmatics
Klíčová slova: komunikace, koreference, anotace korpusu, text (diskurz), textové konektory, diskurzní vztahy, inference, lingvistická metodologie, pragmatika
[1]1 Úvod
V posledních desetiletích je možné jak v domácí, tak ve světové korpusové lingvistice pozorovat velký rozmach: Spolu se stále se zdokonalujícími technickými možnostmi elektronického zpracování a ukládání jazykových dat se kvalitativně i kvantitativně zvyšuje produkce korpusů a jiných elektronických zdrojů. Vzniká tak i množství principů a metodologií, jak tyto zdroje tvořit, co je pro jaký typ jazykových dat a zaměření korpusu vhodné, ať již při samotné kompilaci, či při (stále oblíbenějším) korpusovém značkování. Tato studie je teoreticko-metodologickou úvahou o tom, jak a do jaké míry je v současné době možné korpusově zpracovávat a značit jevy „nadvětné“, jevy textové lingvistiky. Oproti gramatickým pravidlům, která lingvistika nalézá v analýzách „uvnitř věty“, hledají textovělingvistická bádání spíše určité pravidelnosti, tendence či strategie (Dressler – de Beaugrande, 1981). Text (neboli diskurz, v anglicky psaném výzkumu se užívá termínu „discourse“, německá lingvistika preferuje termín „Text“)[2] [242]tedy není souhrnem gramatických pravidel – pak by byl stanovený úkol snazší. Text je jednotkou komunikace a korpusové zpracování jevů, které text textem dělají, je pokusem systematicky zachytit (alespoň některé) jevy komunikační, ze své podstaty spíše nesystémové. Tím se stává tento druh lingvistické analýzy zároveň velkou výzvou pro korpusovou lingvistiku.
Studie je rozdělena na několik částí. Po krátkém přehledu základních prací, které přispěly k etablování textové lingvistiky u nás i ve světě (oddíl 2), a přiblížení základních východisek této studie (oddíl 3) jsou podrobněji popsány zejména ty lingvistické přístupy k analýze textu a jeho koherence, které vyústily ve vznik některého z korpusů se značením nadvětných jevů (oddíl 4). V základních rysech popisujeme principy značení nadvětných jevů v Pražském závislostním korpusu 3.0 (dále PDT). V tomto oddíle také klasifikujeme jednotlivé jevy či aspekty, které se podílejí na textové koherenci. V oddílech 5 a 6 se věnujeme evaluacím konzistence zmíněných anotací. V závěru článku pak na základě našich zkušeností shrnujeme požadavky na deskriptivně adekvátní lingvistický popis různých typů nadvětných jevů v korpusu a jmenujeme také limity takového popisu.
2 Text a korpusová lingvistika
Počátky textové lingvistiky jako samostatné disciplíny lze datovat několik desetiletí zpět, za její průkopníky v Evropě jsou považováni zejména J. S. Petöfi (1971), T. van Dijk (1980), W. Dressler (1972), ve spolupráci s W. Dresslerem R.-A. de Beaugrande (1981) a M. A. K. Halliday a R. Hasan (1976), v českém prostředí pak svými pracemi významně přispěli především F. Daneš (1985), J. Hoffmannová (1983, 1984) a J. Hrbáček (1994).[3] Přes rozvoj výzkumu zabývajícího se nejrůznějšími aspekty textové lingvistiky a přes jasné pokroky korpusové lingvistiky se kombinací těchto témat (textové jevy a korpusové zpracování) dostáváme do víceméně neprobádané oblasti.
Metodologie vytváření korpusu se musí řídit především cílem, který má daný korpus splnit. Většina velkých známých korpusů (série SYN v Českém národním korpusu, British National Corpus atd.) vznikla primárně pro lingvistický [243]výzkum. Existují však i korpusy, jejichž hlavním či alespoň důležitým cílem je sloužit komputačním účelům – v této souvislosti zmiňme zejména korpusy paralelní, dvou- či vícejazyčné, sloužící jako trénovací a testovací data pro strojový překlad a jiné aplikace zpracovávající přirozený jazyk. V neposlední řadě jsou jazykové korpusy určitým ověřovacím prostorem pro tu či onu lingvistickou teorii, na jejímž základě byla daná korpusová metodologie zpracována.
První vlaštovky v oblasti tzv. „diskurzních“ korpusů, tj. korpusů, které převážně ručním značením zpracovávají některé aspekty textové lingvistiky, sledují všechny tři zmíněné motivace. Z lingvistického hlediska je jejich společným cílem zejména popsat, jakými způsoby je v textu realizována koherence, popsat, co dělí smysluplný text od pouhé posloupnosti vět. Z hlediska komputačního mají tyto analýzy umožnit budoucí modelování koherence a užití různých vlastností textu jako rysů pro nejrůznější jazykové aplikace. Hledisko empirického ověřování teorie se pak zdá být velmi důležité, neboť zakládá plodnou diskusi na téma, které nás zde zajímá především: lze vůbec mluvit o korpusech textových jevů, když text sám je náchylný k mnohoznačné interpretaci, k vlivu pragmatických jevů, je proměnlivým útvarem v závislosti na stylové doméně a komunikačním účelu? A pokud ano, jaké jsou překážky a kde jsou limity takového popisu? Teoretické diskuse v souvislosti se vznikem prvních korpusů textových vztahů ve světě (RST-Treebank, Discourse Graphbank a Penn Discourse Treebank) jsou přiblíženy v kapitole 4.
3 Koherence a inferenční procesy
Na tomto místě udělejme důležitou odbočku, která by měla osvětlit podstatu problematiky značení jevů nadvětných, komunikačních. Klíčovým termínem pro všechny metodologie zpracování či modelování textu je textová koherence, téměř vždy se totiž jedná o modelování jednoho nebo několika aspektů právě textové koherence. Jde o poměrně problematický pojem, pro naše účely budiž koherencí rozuměna významová soudržnost textu,[4] a tedy z hlediska recepce schopnost recipienta přiřadit posloupnosti textových jednotek (autorem zamýšlený) význam neboli textu porozumět. Z kognitivního hlediska pak nejde pouze o schopnost porozumět textu, tedy o komunikaci, ale jedná se o naprosto základní mechanismus našich mentálních operací. Naše mysl neustále vyvozuje určité závěry z podnětů, které se k ní dostávají, např. Kehler (2002, s. 14) v tomto smyslu mluví o všeobecné lidské „touze po koherenci“, o potřebě „vyřešit koherenci“ za pomoci celé řady inferenčních procesů. Stupeň koherence textu pak závisí na množství materiálu, který je třeba domýšlet. Pokud je ho mnoho, nerozumíme. Grosz a kol. (1994, s. 7) tento jev nazývají [244]inferenční zatížení posluchače. Když například vidíme hasiče hasit dům, který nehoří, nedokážeme na základě naší zkušenosti a znalosti světa tuto situaci interpretovat, je pro nás nekoherentní. Jak silná je působnost tohoto mentálního procesu, je pak zřejmé z občasné lidské tendence hledat koherenci i tam, kde není.
Pro oblast textovělingvistického bádání je dobré si tyto kognitivní mechanismy uvědomit zejména proto, že inferenční procesy mohou být velmi komplexní a jejich role v porozumění textu je neoddiskutovatelná. Je zřejmé, že nemůžeme a nechceme analýzy textových jevů omezit na gramatiku textu, zároveň je ale náš úkol ztížen o to, že v korpusu pracujeme s texty, které jsou již mimo svůj komunikační kontext, jsou již pouze vyprázdněnými zápisy. Inferenční zatížení analyzujícího snahou o rekonstrukci komunikačního procesu (vazba textu na souřadnice komunikačního momentu já, ty, teď, tady) tak ještě vzrůstá. Ukazujeme to dále na příkladu (4).
4 Počátky korpusového zpracování nadvětných jevů ve světě[5]
4.1 Rhetorical Structure Theory
Známou textovou teorii Rhetorical Structure Theory (dále RST), vzniklou v 80. letech minulého století (Mann – Thompson, 1988), ověřovali její zastánci již v roce 2002. Tehdy vznikl první soubor textů (žurnalistické angličtiny) značený dle určité ucelené koncepce nadvětných jevů, RST-Treebank (Carlson a kol., 2002). Koncepce RST vychází ze základní hypotézy, že koherentní texty se skládají z minimálních textových jednotek, které jsou navzájem (rekurzivně) propojeny koherenčními vztahy („coherence relations“). V koherentním textu nejsou trhliny ani nelogické výroky. Proto musí existovat nějaký vztah soudržnosti mezi různými částmi textu. Text, respektive textové jednotky a vztahy mezi nimi pak lze reprezentovat pomocí jediného stromového grafu pro celý dokument. Ve vzniklé hierarchické struktuře jsou nejvýše jednotky nejdůležitější či nejbližší celkovému sdělení textu (nuclei), jednotky „závislé“ (satelity) reprezentují informace méně důležité (Mann – Thompson, 1988).
Úspěch i slabiny korpusu RST-Treebank pak otevřely diskusi o možnostech a hranicích korpusového zpracování takto komplexní úrovně jazyka, ale také právě – v obecnější rovině – o možnostech formálně zpracovávat textové jevy – automaticky analyzovat („parsovat“) text, modelovat koherenci, vyhledávat informace či shrnovat obsah. V těsném sledu za korpusem RST-Treebank vznikají další zpracování těch samých dat, Discourse Graphbank (Wolf – Gibson,
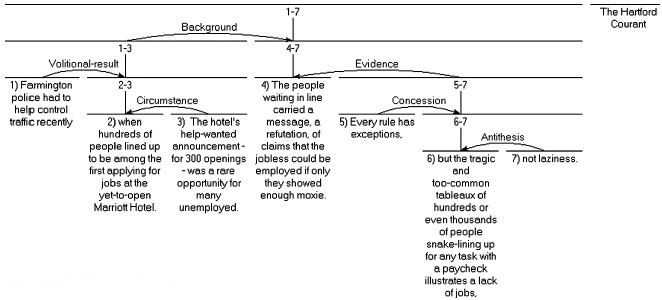
Obr. 1 Příklad RST analýzy[6]
2005), Penn Discourse Treebank I. (Miltsakaki a kol., 2004), pokaždé v jiném metodologickém rámci, formuje se několik velmi odlišných přístupů, jak zpracovávat různé aspekty textu.[7]
Jakkoli RST zůstává průlomem v oblasti systematického zpracování textových jevů korpusovými metodami, bylo vůči ní vzneseno několik zásadních námitek. Zaprvé je to kritika koncepce textu jako stromové struktury. Z matematického hlediska je tím totiž řečeno, že v textu bychom neměli najít takové vztahy mezi jednotkami, které by porušovaly pravidlo projektivního stromu, tedy že neexistují vztahy, které se „kříží“, či vztahy vzdálenějších jednotek. Je velmi pravděpodobné, že uvolněním těchto kritérií (tj. text je stromový graf) získáme další hodnotné informace o tom, jak je realizována koherence. To činí autoři korpusu Discourse Graphbank (Wolf – Gibson, 2005) a na základě značených dat argumentují, že 12,5 % jimi nalezených vztahů neodpovídá kritériím nastaveným RST. Text tudíž podle nich není vhodné reprezentovat jako jedinou stromovou strukturu. Autoři RST-Treebanku pak hodnotí těchto 12,5 % jako číslo natolik nízké, že naopak východiska RST obhajuje. Tyto vztahy dále klasifikují a tvrdí, [246]že se zde nejedná o diskurzní vztahy v pravém slova smyslu, nýbrž že se jedná o jakousi textovou anaforu.[8] Z diskuse vyplývá, že záleží na tom, jaké množství a jaký typ inferencí je při analýze dovoleno užít. Čím méně omezení nastavíme, tím více relevantních souvislostí lze objevit, ale také riskujeme ztrátu stability celého modelu a ve výsledku příliš mnoho možných interpretací.
4.2 Vícevrstevná analýza textu
Druhá obecná námitka vůči RST (a potažmo i Discourse Graphbanku) zní, že přestože se oba modely snaží o precizní definici a klasifikaci repertoáru významových vztahů, které mezi textovými jednotkami lze najít, ve skutečnosti směšují v jednom druhu analýzy několik aspektů či vrstev analýzy textových jevů – rovinu diskurzních vztahů, rovinu tematickou, rovinu referenční, rovinu intenční či ilokuční atd. S novějšími pohledy na možnosti korpusové analýzy textových jevů tak roste požadavek tzv. vícevrstevné analýzy textu (Mehrebenen-Annotation – MEA, Stede, 2008) s vědomím, že tyto vrstvy/aspekty jsou při vytváření srozumitelného textu nejrůznějšími způsoby v interakci.[9]
Samotná existence těchto vrstev (či aspektů) analýzy textových jevů (pod nejrůznějšími názvy) není objevná, například Grosz a Sidner již v roce 1986 mluví o třech různých strukturách textu (lingvistické, intenční a pozornostní)[10], které dohromady přispívají k jeho koherenci. V českém prostředí Hrbáček (1994) rozlišuje textovou koherenci obsahově-sémantickou, funkční (komunikační), pragmatickou a stylovou, jako základy obsahově-sémantické koherence pak jmenuje vztahy koreferenční, vztahy sémantické ekvivalence (kontiguity) a vztahy mezipropoziční. Novým se však stává požadavek vícevrstevné textové analýzy v rámci jednoho korpusu, na stejných jazykových datech.
4.2.1 Jednotlivé vrstvy, jejich specifika a interakce
V tabulce 1 níže jsou vyjmenovány hlavní aspekty/vrstvy analýzy textu tak, jak o nich smýšlejí různé směry textovělingvistického výzkumu. Tento přehled není vyčerpávající ani není jedinou možnou klasifikací. Chybí zde například aktuální členění větné (např. Hajičová, 1993), které se bezpochyby na výstavbě textu podílí, zejména analýzou kontextové zapojenosti výrazů a popisem stří-
| alternativní pojmenování | typické prostředky vyjádření | příklady ručního korpusového zpracování | |
| referenční struktura textu | zájmenná a jmenná koreference, anafora, katafora, exofora | zájmena, zájmenná příslovce, členy, substantiva, shoda přísudku s podmětem atd. | OntoNotes, GNOME, PDT 3.0 a další |
| asociační anafora | vztahy sémantické ekvivalence (kontiguity), „bridging“ | složky významu u jednotlivých slov, kontrast v aktuálním členění | GNOME, Copenhagen Dependency Treebank, PDT 3.0 a další |
| diskurzní vztahy | rematické vztahy, mezipropoziční vztahy, koherenční vztahy, konjunktivní vztahy, nadvětná syntax | textové konektory (spojky, některé částice a příslovce, ustálené víceslovné obraty), alternativní vyjádření konektorů (např. důvodem je) | RST-Treebank, Discourse Graphbank, PDTB, PDT 3.0 a další |
| rétorická struktura | globální struktura textu, hloubková analýza textu, „rhetorical relations“ | textové konektory, rétorické figury apod. | RST-Treebank, Potsdam Commentary Corpus, AnnoDis |
| temporální struktura |
| časová příslovce, slovesný čas atd. | v rámci diskurzních vztahů |
| intenční struktura | ilokuční struktura, komunikační a pragmatické faktory | explicitní vyjádření: účelové věty, účelová doplnění, sloveso „chtít“ a jeho opisy |
|
| tematická struktura | salience, aktivovanost prvků v textu, „attentional state“ | prostředky vyjádření aktuálního členění větného (slovosled, rematizátory aj.) a další |
|
| grafická struktura |
| interpunkce, velká písmena, odstavce, nadpisy apod. |
|
| zvuková struktura |
| intonace, větný přízvuk apod. |
|
Tab. 1 Jednotlivé aspekty/vrstvy lingvistické analýzy textu
dání informace nové a staré, jeho primární místo je však v rámci analýzy věty. Také pragmatická vrstva popisu není samostatně vymezena, zejména proto, že nebývá jasně definováno, co všechno vlastně obsahuje.[11] Přehled má však za úkol ozřejmit směry, kterými se ubírá korpusově zaměřené bádání v oblasti textové koherence. Rétorická struktura textu již byla zmíněna, a přestože je možné ji rozčlenit na několik jiných vrstev, v přehledu je zachována jako svébytný způsob textové analýzy. Dále se pak především zabýváme diskurzními vztahy a referenční strukturou textu jakožto aspekty výrazně reprezentovanými povrchovými formami na straně jedné a asociační anaforou (či vztahy sémantické ekvivalence) [248]jakožto zástupcem pro jev značně podléhající interpretaci na straně druhé. Díky existujícímu zpracování těchto tří aspektů v rámci rozšíření anotací Pražského závislostního korpusu je možné doložit úspěšnost a úskalí těchto zpracování empiricky, viz kapitola 5. Značená data jsou k dispozici ve třetím vydání PDT (Bejček et al., 2013).[12]
4.2.2 Interakce vrstev textové analýzy
Rozlišovat jednotlivé vrstvy analýzy textu je někdy složité, neboť spolupůsobí, či dokonce splývají, pro ilustraci uvádíme tři různé příklady.
Na úrovni jednotlivých jazykových prostředků lze ukázat jasný příklad takové interakce na historickém vývoji spojovacích výrazů – i napříč jazyky lze zaznamenat jejich vznik splynutím předložky a demonstrativa, např. proto = pro + to, přesto = přes + to (podobně např. anglické: hereby, thereafter, německé danach, trotzdem atd.). Tento vývojový proces není ukončen, v češtině dokonce občas může působit psaní těchto spojení zvlášť či dohromady problémy. Vliv koreference (přítomnost referenčního komponentu) na vývoj konektivních prostředků a jejich prostřednictvím na analýzu diskurzních vztahů lze pozorovat i z jiného úhlu, v češtině zejména právě u výrazů, které se mohou psát dohromady i zvlášť. V anotaci diskurzních vztahů v PDT se otázka, zda má být výraz psaný zvlášť v daném případě považován za textový konektor, či nikoli, řídila určením povahy antecedentu referenční části takového výrazu. Pokud se jednalo o antecedent slovesný (propozici), považovalo se spojení s referenčním komponentem za textový konektor (příklad (1), antecetendem zájmena toho je sloveso provozovat). Pokud byl antecedent pouhou entitou, spojení předložky a demonstrativa se za konektor nepovažovalo (příklad (2), antecedentem zájmena tomu je jméno katalog), srovnej Poláková a kol. (2012), odtud i následující příklady.
| Mövenpick provozuje několik desítek hotelů nejen v Evropě, ale i v Asii a Africe. Kromě toho je známý i jako obchodní a potravinářská firma. | |
| British Library vydala stručný katalog knih uvedené tematiky čítající přes šest set položek z majetku knihovny. K tomu lze na místě zakoupit dvě publikace o ruské avantgardní knize, vydané specialistkou Susan Comptonovou. |
Jiným příkladem interakce, či spíše splývání jednotlivých vrstev popisu textových vztahů je prolínání významově-obsahové vrstvy (vrstvy informací) s vrstvou intenční (ilokuční). Na daný problém se opakovaně upozorňuje v literatuře, podrobně se o „disambiguaci rétorické struktury“ pokusil Stede (2008), jeho příklad uvádíme jako (3).
| Přijď domů do šesti hodin. To ještě stihneme zajít nakoupit, než zavře obchod. |
[249]Příklad (3) tak může být analyzován čistě významově jako textová podmínka (když přijdeš brzo, stihneme nakoupit) nebo pragmaticky jako umožnění (tvůj brzký příchod je předpoklad návštěvy obchodu) nebo z hlediska intencí jako motivace (chceme jít do obchodu, proto bys měl přijít brzy). V prvních dvou případech by RST analýza považovala za centrální druhou výpověď, ve třetím případě první výpověď.
Poslední příklad interakce jednotlivých vrstev poukazuje na nutnost více než jedné oddělené analýzy pro plné porozumění textu a popisuje inferenční proces v pozadí. Následující věty (4) jsou krátkým úryvkem ze známé dětské prózy A. A. Milneho, jsou součástí promluvy Medvídka Pú.
| Včely jsou na světě jedině proto, aby dělaly med. A med dělají jedině proto, abych já ho snědl. |
Příklad (4) lze analyzovat z hlediska čistě obsahově-sémantického jako sled kauzálních souvislostí, jako konjunkci účelů. Dozvídáme se o účelu existence včel a o účelu existence medu. Z hlediska analýzy mluvních aktů jde o prosté tvrzení, či dokonce o tvrzení s obecnou platností (o obecném chodu světa). Na jemnější pragmatické úrovni se zde děje jisté vyvozování, mluvčí z faktu A vyvozuje fakt B a dále z faktu B fakt C. V tomto případě je však třeba pokračovat analýzou intencí autora, a to reflektováním skutečnosti, že úryvek textu patří postavě fikčního světa, jejíž konceptualizace světa se neshoduje s naší. Tento nesoulad perspektivy postavy s perspektivou naší (spolu s případnou tendencí zde interpretovat obě účelové věty jako nepravé) dává vzniknout trhlině v koherenci, která musí být zaplněna: Medvídek Pú je „medvěd s nepatrným rozoumkem” a jeho dětský náhled světa je humorným nábojem textu. Pochopení tohoto autorského záměru je v tomto případě nutné nejen k porozumění dané části textu (což se jeví jako logické u jakéhokoli textu), ale také ke správné interpretaci diskurzních (obsahově-sémantických) vztahů ve větách se spojkou aby.
4.3 Lexikální metody, lokální koherence
4.3.1 Penn Discourse Treebank
Vedle zmíněných analýz celé struktury textu v jediné reprezentaci, tzv. hloubkových analýz textu či modelování globální koherence,[13] existují i tzv. lexikálně zakotvené analýzy textu, kterým se také říká „mělká analýza textu“ či „modelování lokální koherence“[14]. Popis textových jevů (zde konkrétně popis diskurzních vztahů) v lexikálně založených metodologiích spočívá v identifikaci tzv. textových konektorů (konektivních prostředků) a v klasifikaci významových vztahů jimi vyjádřených. Prvním korpusem značeným podle této metodologie je anglický [250]Penn Discourse Treebank (dále PDTB I, Miltsakaki a kol., 2004, PDTB II, Prasad a kol., 2008), který se stal inspirací pro zpracování diskurzních vztahů v mnoha dalších jazycích včetně češtiny.[15] Textový konektor je zde chápán jako predikát binárního textového vztahu, přijímá tedy právě dva argumenty (textové jednotky). Textovými konektory je většina spojek a spojovacích výrazů vyjadřujících druh syntaktického vztahu mezi větami uvnitř souvětí (v příkladu (5) Protože propojující úseky (b) a (c)) a dále spojky a převážně adverbiální a částicové výrazy, které signalizují takové spojování, respektive připojování, přes hranice jednoho větného celku (v příkladu (5) ale propojující (a) a (b+c)). Textovými konektory v širším slova smyslu pak jsou alternativní vyjádření konektorů základních, např. spojení Tím pádem propojující (b+c) a (d).
| (a) Máme zaměstnance, které občas vysíláme na služební cestu. | |
|
| (b) Protože je ale v naší firmě několikanásobně více zaměstnanců než služebních vozidel, |
|
| (c) musí v případě nouze jet vlastním autem. |
|
| (d) Tím pádem máme problém se silniční daní. |
Nejmenší textovou jednotkou (argumentem) je realizovaná propozice, tj. určitý děj, stav, proces atd. Doposud se zachycování diskurzních vztahů v korpusech soustředilo pouze na vztahy mezi propozicemi realizovanými větou s určitým tvarem slovesa, jedná se ovšem o praktické řešení; z obecného hlediska je za textový argument považována jakákoli realizace propozice, zejména pak deverbativní substantiva.
Anotační schéma PDTB dále rozlišuje tzv. explicitní a implicitní textové vztahy. Explicitní jsou vztahy s povrchově přítomným textovým konektorem, implicitní jsou takové, kde sice povrchově přítomný konektor není, ale je možné jej doplnit mezi dva textové úseky, mezi kterými diskurzní vztah existuje, viz příklad (6) a dále příklady (7) a (8) níže. V PDT se zatím anotace tohoto typu nevyskytuje, podrobněji se však problematikou značení implicitních vztahů pomocí vložení konektoru v současnosti zabýváme, více v kapitole 6.1.
| Charakter lázní Teplice umožňuje, že u tuzemských pacientů převažuje komplexní léčba nad příspěvkovou. Jde o poměr 73 procent ku 21 procentům. |
Metodologie PDTB bývá označována za modelování lokální koherence, neboť zachycuje především vztahy sousedních jednotek. Na příkladu (5) výše je vidět, že i tyto vztahy mohou tvořit hierarchie – vztah signalizovaný konektorem protože je plně zahrnut ve vztahu signalizovaným konektorem ale. Neexistuje ovšem žádné tvrzení o tom, jak vypadá celková struktura textu, nepředpokládá se jediná spojitá struktura.
[251]4.3.2 Nadvětné jevy v Pražském závislostním korpusu
Pražský závislostní korpus 3.0 (Bejček et al., 2013) je soubor českých žurnalistických textů (50 000 vět) anotovaný na několika úrovních jazykového popisu v souladu s teorií funkčního generativního popisu (např. Sgall, 1967). Třetí verze nabízí mimo jiné ruční značení čtyř aspektů textových jevů: diskurzních vztahů, textové koreference (včetně anaforických výrazů první a druhé osoby), vztahů asociační anafory a žánrové příslušnosti textů. Anotace byla (kromě klasifikace žánrové) provedena na závislostních stromech tektogramatické (tj. hloubkové) roviny, což umožnilo využít při analýze textu některých vlastností nižších rovin popisu. Pro vztahy diskurzní to byly zejména některé vztahy syntaktické závislosti a koordinace, analýza spojovacích prostředků a některých výrazů částicových a adverbiálních s připojovací funkcí, pro koreferenci pak rekonstrukce elips a zejména nevyjádřených podmětů. Anotace diskurzních vztahů v PDT je inspirována lexikálním přístupem korpusu Penn Discourse Treebank a z důvodu ověřitelnosti tohoto přístupu na typologicky jiném jazyce se pražské anotační zásady liší jen v jednotlivostech. Jediný výrazný rozdíl je v samotném procesu anotací – většina vnitrovětně realizovaných textových vztahů v PDT nebyla znovu ručně značena, nýbrž byla automaticky extrahována a přejata do reprezentace diskurzních vztahů. Podrobněji o zachycování textových jevů v PDT viz Poláková a kol., 2013.[16]
5 Otázka anotátorské shody
Analýza typu RST čelí ještě jednomu problému, který se zdá být obecným problémem jakéhokoli značkování komplexnějších jazykových jevů, potažmo značkování významu. Je velmi závislá na interpretaci anotátora, a čím delší text je analyzován, tím více je zřejmé, že lze vytvořit více relevantních reprezentací. Nízká anotátorská shoda u tohoto typu analýzy tedy otvírá zásadní otázku o spolehlivosti této koncepce jako korpusové metody.
Předpokládáme, že určování lemmat či morfologických kategorií slov v konkrétním kontextu je úkol znatelně snazší. Doložit to lze (alespoň pro češtinu) jak vysokou mezianotátorskou shodou ručních anotací – 95 % shody na nevyřešených případech po automatické morfologické analýze (Bémová a kol., 1999); 97 % shody na všech slovech (Hajič, 2005) –, tak úspěšností automatických taggerů – současný stav výzkumu ukazuje úspěšnost okolo 97 % pro angličtinu a francouzštinu (Manning, 2011), okolo 96 % pro češtinu (Spoustová, 2008). Anotace syntaktická, ať již závislostní, či složková, spočívá u většiny korpusů (treebanků) v opravování výstupu automatické syntaktické analýzy (parsingu). Zde se pak většinou významně liší shoda na samotné struktuře věty (tj. konečná [252]podoba stromu) od shody v přiřazení syntakticko-sémantických značek jednotlivým vztahům mezi prvky věty (hranám stromu): druhý úkol se zdá být obtížnější. V Pražském závislostním korpusu byla naměřena shoda na struktuře podkladové roviny věty (tektogramatické roviny) 91 % a shoda v přiřazení sémantických značek 84 % (tektogramatické funktory, 67 značek, Hajičová a kol., 2002).[17] Ve složkovém treebanku němčiny Negra je vidět stejná tendence: uvádí se shoda 93,72 % na struktuře stromu a 88,53 % na označení gramatických funkcí (45 značek, Brants, 2000).
Anotace nadvětných jevů pak vykazují čísla stejná či ještě nižší. V PDT se měřila anotátorská shoda u všech typů anotace nadvětných jevů na překryvech dat vždy dvou anotátorů, anotátoři nevěděli, která část jejich dat je k evaluaci určena. U diskurzních vztahů, respektive u značení primárně jejich mezivětných realizací, byla zaznamenána shoda v rozpoznání diskurzního vztahu F1 = 0,83 (měřeno jako shoda na identifikaci textového konektoru), procentuální shoda v určení významového typu vztahu (měřeno na vztazích rozpoznaných oběma anotátory) pak byla 0,77 (22 značek, Mírovský a kol., 2010). Srovnatelným údajem v PDTB 2.0 je shoda 0,8 na typu vztahu (23 značek, Prasad a kol., 2008).[18]
Měření shody u anotace koreference v PDT (viz zejména Nedoluzhko, 2011) bylo založeno na koreferenčních řetězcích, tj. za shodu bylo považováno, pokud oba anotátoři označili vztah mezi dvěma stejnými uzly, a to buď přímo, nebo tranzitivně přes další uzly. F1 v tomto případě bylo 0,72, procentuální poměr shody na typu koreference 0,9 (pouze 2 značky – specifická a generická koreference, Nedoluzhko – Mírovský, 2013). Nejlépe srovnatelným výsledkem je evaluace anotace koreferenčních vztahů v korpusu OntoNotes, kde byla podobnou (i když ne stejnou) metodou měření zaznamenána anotátorská shoda na angličtině 80,9 % pro novinové a 78,4 % pro časopisecké texty. Pro čínštinu byla shoda 73,6 % pro novinové texty a 74,9 % pro časopisecké texty (Pradhan a kol., 2012).
Měření F1 pro asociační anaforu v PDT, založené opět na označení vztahu mezi stejnými dvěma uzly, dosáhlo jen hodnoty 0,46, určení typu asociačního vztahu pak bylo úspěšnější – 0,92 (9 značek, Nedoluzhko – Mírovský, 2013). Tento výsledek lze zhruba srovnat s měřením F1 při anotaci nizozemských textů [253]v korpusu COREA. Jejich shoda na novinových textech byla 0,39 (Hendrickx a kol., 2011).
Jsme si vědomi toho, že údaje o shodě u různých projektů nejsou navzájem přímo srovnatelné – jedná se o analýzy různých lingvistických jevů, používají se různě rozsáhlé sady značek, anotační zásady mohou být různě konzistentní a v neposlední řadě se užívají i různé evaluační míry. Přesto však považujeme výsledky těchto evaluací za zřejmý důkaz rozdílné náročnosti různých anotačních úkolů.
Sledujeme zde tendenci, která činí anotaci jevů nadvětných výzvou: zdá se, že čím více abstrahujeme od jazykové formy, čím „vyšší“ (či „hlubší“) úroveň jazyka se snažíme popsat, tím se zvyšuje možnost rozdílných interpretací a tím těžší je dosáhnout vysokých hodnot anotátorské shody. Obavu z toho, zda tedy má smysl se analýzou nadvětných jevů korpusovými metodami vůbec zabývat, lze alespoň částečně odstranit akceptováním skutečnosti, že čísla shody v takto komplexní oblasti popisu přirozeně a zákonitě musí být nižší. Naopak, „příliš vysoká shoda u nějakého typu analýzy textových jevů by mohla vzbuzovat podezření, že daná analýza spočívá na neadekvátních základech“.[19]
Na základě dosavadních zkušeností s anotací různých jazykových jevů lze vysledovat kromě ubývající shody ještě jednu tendenci, že totiž, zůstaneme-li u formy, budeme-li se maximálně držet konkrétních jazykových výrazů v textu, můžeme s vysokou úspěšností značit i jevy tak komplexní, jako jsou prostředky vyjádření textové koherence.[20] Z druhé strany naopak, pokoušíme-li se zachytit implicitní znaky koherence, značíme-li význam bez přítomnosti jasné jazykové formy neboli takzvanou „neviditelnou sémantiku“, začínají se relevantní interpretace množit, projevuje se víceznačnost i vágnost textu a spolehlivost takového přístupu jako korpusové metody klesá, jak je vidět na příkladu RST. Tuto tendenci dále dokládáme v kapitole 6 analýzou dvou nadvětných jevů s tradičně nízkou anotátorskou shodou.
6 Jevy s tradičně nízkou anotátorskou shodou
6.1 Analýza implicitních diskurzních vztahů
Anotace tzv. implicitních vztahů je ve všech známých korpusových projektech problematickou záležitostí, anotátorská shoda je v tomto případě velmi nízká. V rámci návrhu na další rozšíření PDT jsme provedli pokusnou anotaci těchto vztahů (tj. v povrchové rovině se nevyskytuje žádný textový konektor, který by daný vztah vyjadřoval). Po zkušenostech se zachycováním implicitních diskurz[254]ních vztahů v PDTB 2.0, kde jejich ruční anotace proběhla plošně, jsme se zprvu pokusili omezit faktory, které již tradičně způsobují neshody: Ke studii byly vybrány tři texty z domény přístupné znalostem anotátorů (kulturní recenze), texty krátké o délce okolo 35 vět. Anotaci prováděli dva nejzkušenější anotátoři, a to tak, že mezi každé dva sousední větné celky (kromě hranic odstavců a kromě míst, kde již byl konektor explicitní) vkládali značku pro nejlépe odpovídající typ diskurzního vztahu. Kromě jednotlivých typů významových vztahů byla i možnost značit spojení daných dvou vět jako koreferenční či jako založené na asociační anafoře. Procentuální shoda činila 49 % na typu vztahu. Při mírnějším hodnocení – jakýkoli typ diskurzního vztahu nebo vztah koreference nebo asociační anafory (tj. výběr ze tří kategorií) – byla shoda nepatrně vyšší, a to 58 %. Nejvíce problematické se ukázalo rozlišení mezi vztahy sémantického rozšíření (konjunkce, specifikace, ekvivalence atd.) a vztahy založenými pouze na koreferenci, srovnej příklad (7), který byl shodně interpretován oběma anotátory jako specifikace, a příklad (8), který jeden anotátor hodnotil jako konjunkci (v metodologii PDTB by byla vložena spojka „a“) a druhý jako případ navazování prostřednictvím asociační anafory. Ačkoli se anotátoři po následném společném rozboru ve většině případů shodli na jednotné interpretaci, výsledky nás přesvědčily o tom, že je nutné anotaci implicitních vztahů před jakýmkoli plošným zachycováním v korpusu věnovat ještě náležitou pozornost.
| Zvláště jímavá je fotografie Burljuka z jeho amerického pobytu, kde stále zdůrazňoval svou futuristickou image. Jednu tvář má pomalovanou, připomíná tetování, v uchu náušnici, na hlavě cylindr, pruhovanou křiklavou vestu… | |
| Někteří si vystoupení dudáckých souborů zaznamenávali na videokamery, případně nahrávali na magnetofony. Bylo i nebylo co nahrávat. |
6.2 Asociační anafora
Vedle koreference existuje řada dalších významových vztahů, které umožňují posluchači chápat některý výraz jako známý v důsledku toho, že v předcházejícím kontextu se objevil jiný výraz, který, ač nekoreferenční se svým antecedentem, s ním je jistým způsobem významově spjatý. Pro označení těchto vztahů užíváme termín asociační anafora[21] (Nedoluzhko, 2011).
V rámci zachycení asociační anafory v PDT se rozlišuje následujících šest vztahů, značí se však celkem devíti značkami, neboť u tří z těchto vztahů hraje roli jejich směr, viz níže:
– metonymický vztah části a celku (strop – místnost, auto – volant)
– vztah mezi množinou a podmnožinou / prvkem množiny (studenti – někteří studenti)
[255]– vztah mezi objektem a na něm definovanou unikátní funkcí (trenér – fotbalový tým)
– kontrast pro koherenčně relevantní antonyma (tento rok – příští rok)
– anafora pro explicitní anaforické vztahy bez koreference (druhá světová válka – v tomto čase)
– blíže nespecifikovaná skupina (značka REST), která zachycuje především takové asociační vztahy, jako je lokace – obyvatelé (Praha – Pražáci) nebo rodinná příslušnost (otec – syn)
Ačkoli je z metodologie značení asociační anafory v PDT patrná snaha autorů o jasné definice kategorií a důsledné dodržování předmětu analýzy, charakter takového úkolu se ukazuje při zpracování reálných textů velmi zrádný. Jak ukazují výsledky shody, není problémem rozlišování typů asociačního vztahu – když už se na existenci asociačního vztahu anotátoři shodnou, přiřadí mu zpravidla i stejnou značku (96 %). Spíše se často stává, že dva anotátoři značí v textu zcela rozdílné vztahy, tj. že průnik jejich analýz je malý. Jako nejpřípadnější vysvětlení se jeví fakt, že tento typ analýzy primárně značí v textu přímo význam, a nevychází tedy z jazykové formy, jak tomu bylo u značení konektorů. Samotné jazykové prostředky v textu v tomto případě nijak nesignalizují svou roli v asociačních vztazích, jejich primární rolí není (jako u konektorů či zájmen) propojování textových jednotek a vytváření koherence, to zde činí anotátor sám na základě svých inferenčních procesů.
Na příkladech analýzy implicitních diskurzních vztahů a vztahů asociační anafory je dle našeho názoru dobře vidět, kdy se korpusová analýza nadvětných jevů dostává blízko k hranicím spolehlivosti. Další cesty vidíme dvě, a samozřejmě jsou závislé na účelu, který má daná analýza přinést. Buď lze na základě nabytých zkušeností dosavadní metodologie upravit či zpřísnit a očekávat nárůst shody za cenu možné ztráty některých relevantních informací, nebo rezignujeme na dosažení vyšší shody, ale zato získáme podrobnější analýzu, i když ji bude třeba dále zpracovat především z hlediska konzistence.
7 Shrnutí
Zachycování jevů nadvětných korpusovými metodami je úkolem zcela specifickým, a to především proto, že v rámci textu nelze mluvit o pravidlech a souvislostech takové povahy, jaké lze najít v rámci věty. Teorie textu a jeho významové soudržnosti (koherence), které byly doposud testovány značením skutečných jazykových dat, ukazují, že korpusová zpracování textových jevů možná jsou, je však třeba mít na paměti následující skutečnosti:
Je třeba nesměšovat jednotlivé aspekty/vrstvy analýzy textu, ale zároveň nezapomenout na to, že jsou navzájem propojeny a na koherenci textu se spolupodílejí, a to různou měrou. Postulovat jednu spojitou strukturu textu je možné jedině [256]tehdy, pokud připustíme, že se tak děje účastí a interakcí těchto různých aspektů. Princip zachycení textu jako jediné spojité struktury se tedy jeví z deskriptivního hlediska podspecifikovaný.
Dalším poznatkem je fakt, že metodologie vycházející z jazykových forem (konkrétních výrazů v textu), jejichž prvotní funkcí je textové spojování, propojování či odkazování, dosahují lepší konzistence a vyšší anotátorské shody než metodologie zaměřující se přímo na hledání těchto významových propojení. Doložili jsme to na relativní konzistenci anotací textových konektorů a koreferujících výrazů v různých korpusových projektech na straně jedné a na problematičnosti stejného značení tzv. implicitních vztahů a vztahů asociační anafory na straně druhé. Reprezentace významu, která se nezakládá na analýze konkrétní povrchové formy, nýbrž jaksi teprve vyplývá z jazykového i komunikačního kontextu, daleko více podléhá interpretaci recipienta a dle našeho názoru tak rýsuje poměrně jasnou hranici toho, čeho lze spolehlivě dosáhnout v analýzách textu korpusovými metodami.
LITERATURA
ADAMEC, P. (1995): Konektivní částice a jiné textově propojovací výrazy v současné češtině, In: Přednášky z 37. a 38. běhu LŠSS. Praha: Univerzita Karlova, s. 59–64.
BEJČEK, E. et al. (2013): Prague Dependency Treebank 3.0 [online]. Praha: Ústav formální a aplikované lingvistiky MFF UK. <http://ufal.mff.cuni.cz/pdt3.0>.
BÉMOVÁ, A. – HAJIČ, J. – VIDOVÁ HLADKÁ, B. – PANEVOVÁ, J. (1999): Morphological and Syntactic Tagging of the Prague Dependency Treebank. In: Journes ATALA – Corpus annotes pour la syntaxe; ATALA Workshop – Treebanks, Paříž.
BRANDTS, T. (2000): Inter-Annotator Agreement for a German Newspaper Corpus. In: Proceedings of the 2nd International Conference on Language Resources and Evaluation. Athens.
CARLSON, L. – MARCU, D. – OKUROWSKI, M. E. (2002): RST Discourse Treebank. Philadelphia, PA: Linguistic Data Consortium.
DANEŠ, F. (1985): Věta a text. Praha: Academia.
DRESSLER, W. (1972): Einführung in die Textlinguistik. Tübingen: Niemeyer.
DRESSLER, W. – DE BEAUGRANDE, R.-A. (1981): Introduction to Text Linguistics. London – New York: Longman.
GROSZ, B. – JOSHI, A. – WEINSTEIN, S. (1994): Centering: A Framework for Modeling the Local Coherence of Discourse. Computational Linguistics, 2, s. 203–225.
GROSZ, B. – SIDNER, C. (1986): Attention, Intentions and the Structure of Discourse. Computational Linguistics, 6, s. 175–204.
HAJIČ, J. (2005): Complex corpus annotation: The Prague dependency treebank. In: M. Šimková (ed.), Insight into the Slovak and Czech Corpus Linguistics 2005. Bratislava: Veda, s. 54.
HAJIČOVÁ, E. (1993): Issues of Sentence Structure and Discourse Patterns. Praha: Univerzita Karlova.
[257]HAJIČOVÁ, E. – PAJAS, P. – VESELÁ, K. (2002): Corpus Annotation on the Tectogrammatical Layer: Summarizing the First Stages of Evaluations. The Prague Bulletin of Mathematical Linguistics, 77, s. 5–18.
HALLIDAY, M. A. K. – HASAN, R. (1976): Cohesion in English. London: Longman.
HAUSENBLAS, K. (1964): On the characterization and classification of discourses. In: Travaux linguistiques de Prague 1. Praha: Academia.
HAUSENBLAS, K. (1971): Výstavba jazykových projevů a styl. Praha: Univerzita Karlova.
HENDRICKX, I. – DE CLERCQ, O. – HOSTE, V. (2011): Analysis and Reference Resolution of Bridge Anaphora across Different Text Genres. In: I. Hendrickx – S. Lalitha Devi – A. Branco – R. Mitkov (eds.), Anaphora Processing and Applications. Springer, s. 1–11.
HOFFMANNOVÁ, J. (1983): Sémantické a pragmatické aspekty koherence textu. Praha: Ústav pro jazyk český ČSAV.
HOFFMANNOVÁ, J. (1984): Typen der Konnektoren und deren Anteil an der Organisierung des Textes. In: Text and the Pragmatic Aspects of Language. Praha: Ústav pro jazyk český ČSAV, s. 23–39.
HRBÁČEK, J. (1994): Nárys textové syntaxe. Praha: Trizonia.
KEHLER, A. (2002): Coherence, Reference, and the Theory of Grammar. Stanford: CSLI Publications.
MANN, W. C. – THOMPSON, S. A. (1988): Rhetorical Structure Theory: Toward a functional theory of text organization. Text, 8, s. 243–281.
MANNING, CH. D. (2011): Part-of-Speech Tagging from 97% to 100%: Is It Time for Some Linguistics? In: A. Gelbukh (ed.), Computational Linguistics and Intelligent Text Processing, 12th International Conference, CICLing 2011, Proceedings, Part I. Springer, s. 171–189.
MARCU, D. – AMORRORTU, E. – ROMERA, M. (1999): Experiments in Constructing a Corpus of Discourse Trees. In: Proceedings of the ACL Workshop on Standards and Tools for Discourse Tagging. College Park, MD: University of Maryland, s. 48–57.
MILTSAKAKI, E. – PRASAD, R. – JOSHI, A. – WEBBER, B. (2004): The Penn Discourse Treebank. In: Proceedings of the 4th International Conference on Language Resources and Evaluation. Lisabon, s. 2237–2240.
MLADOVÁ, L. (2008): Od hloubkové struktury věty k diskurzním vztahům. Diskurzní vztahy v češtině a jejich zachycení v anotovaném korpusu. Praha: Filozofická fakulta Univerzity Karlovy v Praze.
NEDOLUZHKO, A. (2011): Rozšířená textová koreference a asociační anafora. Koncepce anotace českých dat v Pražském závislostním korpusu. Praha: Ústav formální a aplikované lingvistiky MFF UK.
NEDOLUZHKO, A. – MÍROVSKÝ, J. (2013): Annotators’ Certainty and Disagreements in Coreference and Bridging Annotation in Prague Dependency Treebank. In: Proceedings of the Second International Conference on Dependency Linguistics. Praha: Matfyzpress, s. 236–243.
PEŠEK, O. (2011): Argumentativní konektory v současné francouzštině a češtině. Systémové srovnání a analýza okurenční respondence. České Budějovice: Acta Philologica Universitatis Bohemiae Meridionalis.
PETÖFI, J. S. (1971): Transformationsgrammatiken und eine ko-textuelle Texttheorie: Grundfragen und Konzeptionen. Frankfurt am Main: Athenäum.
[258]POESIO, M. (2004): The MATE/GNOME Proposals for Anaphoric Annotation, Revisited. In: Proceedings of The 5th SIGdial Workshop on Discourse and Dialogue. Boston.
POLÁKOVÁ, L. – JÍNOVÁ, P. – MÍROVSKÝ, J. (2012): Interplay of Coreference and Discourse Relations: Discourse Connectives with a Referential Component. In: Proceedings of the 8th International Conference on Language Resources and Evaluation. Istanbul, s. 146–153.
POLÁKOVÁ, L. a kol. (2013): Introducing the Prague Discourse Treebank 1.0. In: Proceedings of the 6th International Joint Conference on Natural Language Processing. Asian Federation of Natural Language Processing, s. 91–99.
PRADHAN, S. a kol. (2007): Ontonotes: A unified relational semantic representation. In: Proceedings of the International Conference on Semantic Computing. Washington, D.C.
PRASAD, R. a kol. (2008): The Penn Discourse Treebank 2.0. In: Proceedings of the 6th International Conference on Language Resources and Evaluation. Morocco, s. 2961–2968.
SGALL, P. (1967): Generativní popis jazyka a česká deklinace. Praha: Academia.
SPOUSTOVÁ, D. (2008): Combining Statistical and Rule-Based Approaches to Morphological Tagging of Czech Texts. The Prague Bulletin of Mathematical Linguistics, 89, s. 23–40.
STEDE, M. (2008): Disambiguating rhetorical structure. Research on Language and Computation, 6, s. 311–332.
TÁRNYIKOVÁ, J. (2002): From text to texture. An introduction to processing strategies. Olomouc: Univerzita Palackého v Olomouci.
VAN DIJK, T. A. (1980): Text and Context: Explorations in the Semantics and Pragmatics of Discourse. London: Longman.
WEBBER, B. – JOSHI, A. – STONE, M. – KNOTT, A. (2003): Anaphora and Discourse Structure. Computational Linguistics, 29, s. 545–587.
WOLF, F. – GIBSON, E. (2005): Representing discourse coherence: A corpus-based study. Computational Linguistics, 31, 249–287.
[1] Tento výzkum vznikl za podpory projektu GAČR P406/12/0658 Koreference, diskurs a aktuální členění v kontrastivním pohledu, projektů MŠMT Kontakt LH14011 Vícejazyčná korpusová anotace jako podpora jazykových technologií a LINDAT-CLARIN LM2010013 a Specifického vysokoškolského výzkumu Univerzity Karlovy 260 104.
[2] V této studii chápeme termínem text jazykový projev v širokém slova smyslu, tedy i jazykový projev mluvený. Termínem diskurzní vztahy rozumíme významové vztahy mezi textovými (či diskurzními) jednotkami. Tyto vztahy mohou být signalizovány konektorem (výrazy jako ale, neboť, následně, na druhou stranu apod.), ale mohou být i implicitní (bez konektoru). Jiná možná označení pro diskurzní vztahy používaná v literatuře se ukázala být problematická: textové vztahy lze chápat šíře, mezivýpovědní významové vztahy jsou vzhledem k chápání pojmu výpověď naopak příliš úzké, mezipropoziční vztahy by zahrnovaly i vztahy řídící věty a jejího valenčního doplnění. Je nezbytné doplnit, že diskurzní vztahy se mohou vyskytovat i v rámci jedné věty, a proto je užívání pojmu nadvětné jevy lehce nepřesné. Pro obecnou představu o dané problematice však slova „nadvětný“ s touto výhradou užíváme. K problematice terminologie v textové lingvistice srovnej Mladová (2008, s. 24).
[3] Stylistikou a stavbou textů se zabýval především K. Hausenblas (1964, 1971), dále k textovělingvistickým bádáním různými tématy přispěli například P. Adamec (1995), J. Tárnyiková (2002), O. Pešek (2011) a další.
[4] Kohezí pak rozumíme soudržnost formální.
[5] V kapitole 4 zatím necháváme stranou korpusy zpracovávající referenční strukturu textu i celý fenomén textové koreference. Vrátíme se k nim okrajově v kapitole 5 o anotační shodě a v kapitole 6 o anotaci asociační anafory v PDT. Podrobněji se jim v této studii ovšem nevěnujeme, jejich základní přehled viz Poláková a kol. (2013).
[6] Příklad je převzat z http://www.sfu.ca/rst/02analyses/published.html. Český překlad: „1) Farmingtonská policie musela nedávno regulovat dopravu, 2) když stovky lidí vytvořily frontu s cílem být mezi prvními uchazeči o pracovní místa v nově otevírajícím hotelu Marriot. 3) Oznámení hotelu o nabídce tří stovek pracovních míst bylo vzácnou příležitostí pro mnoho nezaměstnaných. 4) Lidé čekající ve frontě přímo vyvraceli platnost oněch tvrzení, že nezaměstnaní mohou získat práci, jen projevit dostatek odvahy. 5) Každé pravidlo má výjimku, 6) ale tragický a až příliš běžný pohled na stovky či dokonce tisíce lidí čekajících na jakoukoli zaplacenou práci ukazuje na nedostatek pracovních míst, 7) ne na lenost.“
[7] Další korpusy textových jevů vzniklé ve světě později (ač třeba na jiných teoretických základech) zde nezmiňujeme, protože se již výrazněji nepodílely na vývoji oboru. Jejich přehled viz Poláková a kol. (2013).
[8] B. Webber a kol. (2003) považují některé textové konektory za anaforické, srov. then v jejich příkladu (s. 7), které se neváže k propozici c, nýbrž k b,: a, John loves Barolo. b, So he ordered three cases of the ’97. c, But he had to cancel the order d, because then he discovered he was broke. Tyto konstrukce jsou však velmi okrajové.
[9] Termínu „vrstva analýzy“ pro překlad anglického „layer“ (multilayer analysis) či německého „Ebene“ používáme proto, abychom jednak zamezili záměně s úrovněmi či rovinami analýzy ve stratifikačním popisu jazyka obecně a jednak proto, že slovo vrstva méně implikuje hierarchičnost úrovní – nic takového ve vrstvách popisu textových jevů nepředpokládáme.
[10] linguistic structure, intentional structure, attentional state (Grosz – Sidner, 1986, s. 177)
[11] Může zahrnovat intenční strukturu, komunikační funkce a analýzu mluvních aktů, subjektivitu, pragmaticky chápané diskurzní vztahy, inference, presupozice atd.
[12] PDT 3.0 je k dispozici zdarma ke stažení z repozitáře Lindat (http://hdl.handle.net/11858/00-097C-0000-0023-1AAF-3) v licenci Creative Commons.
[13] deep discourse parsing, global coherence modeling
[14] shallow discourse parsing, local coherence modeling
[15] Dle našich vědomostí vznikly v nedávné době elektronické zdroje inspirované metodologií PDTB pro turečtinu, arabštinu, hindštinu, čínštinu, němčinu, francouzštinu a italštinu. Jejich přehled viz Poláková a kol. (2013).
[16] A též na webových stránkách projektu http://ufal.mff.cuni.cz/pdt3.0/.
[17] Shoda na syntaktické anotaci se obvykle jednotně měří jako vzájemná shoda anotátorovy a referenční intepretace, popřípadě jako vzájemná shoda dvou anotátorů mírou F1-score, která je harmonickým průměrem přesnosti a úplnosti (precision a recall) jedné anotace vůči druhé.
[18] V publikovaných evaluacích RST-Treebanku udávají autoři shodu pouze pomocí míry Cohenova kappa (κ), jež zohledňuje pravděpodobnost náhodné shody dvou analýz. Jejich výsledky dosahují hodnot kappy 0,73–0,79 u segmentace textů na základní jednotky (uzly stromu), 0,66–0,74 u nuklearity vztahu dvou jednotek (tj. jejich vzájemná „závislost“ ve stromě) a 0,54–0,64 u přiřazení typu rétorického vztahu (73 značek), přičemž hodnoty vyšší než 0,6 lze dle autorů považovat za uspokojivou shodu (Marcu a kol., 1999, s. 54). Pro naše účely je tento způsob evaluace sice málo vypovídající, nicméně sami autoři jsou si vědomi nejednoznačnosti textu a existence mnoha relevantních interpretací při takto komplexním úkolu.
[19] Citujeme postřeh A. Joshiho na workshopu k metodologii zachycování nadvětných jevů, Praha 2011.
[20] Dokládají to i zkušenosti zahraničních badatelů: „Conjunctive relations [= diskurzní vztahy, pozn. aut.] are links that can be read off the text surface without performing ,deep‘ inferences.“ (Stede, 2008, s. 319)
[21] v anglicky psané literatuře „bridging“, „indirect anaphora“ či „associative anaphora“
Ústav formální a aplikované lingvistiky MFF UK
Malostranské náměstí 25, 118 00 Praha 1
polakova@ufal.mff.cuni.cz
Naše řeč, ročník 97 (2014), číslo 4–5, s. 241-258
Předchozí Magda Ševčíková: Zjišťování slovotvorné produktivity z korpusových dat: přípony odvozující názvy vlastností
Následující Lucie Chlumská, Olga Richterová: Překladová čeština v korpusech
© 2011 – HTML 4.01 – CSS 2.1