
Identifikace konstituentů kompozit u předškolních dětí
Anna Kadlecová, Marek Nagy, Barbara Mertins, Sandra Donevska
[Články]
Identification of compound constituents by Czech preschool children
The paper presents research concerned with the ability of children to identify Czech compound constituents and the factors affecting this ability. It focuses on the constituent family size effect, i.e. the number of compounds sharing the constituent (type frequency), and it also compares the results with an English study by Krott and Nicoladis (2005). Unlike the English study, the Czech data do not confirm the family size effect on the child’s success during the identification. The primary factor seems to be the knowledge of the motivating word. Our paper discusses differences in Czech and English compounding and points out some problems of the reliability of the results achieved using a child-questionning method (“Why do we call a merry-go-round a merry-go-round?”).
Key words: compounding, family size, first language acquisition, type frequency, word-formational motivation
Klíčová slova: kompozice, velikost rodiny, osvojování prvního jazyka, frekvence typů, slovotvorná motivace
[*]1 Úvod
Jednou ze základních otázek při výzkumu osvojování mateřského jazyka je, jaké mechanismy řídí a umožňují ovládnutí produktivní povahy jazyka. To znamená kdy a jakými cestami začne dětská mysl reprezentovat a používat jazyk jako typ znalosti, jejímž základním rysem je nejen schopnost vnímat jednotky jazyka jako vnitřně utvářené, ale zároveň ruku v ruce s tím tyto jednotky – na základě porozumění principům jejich stavby a strukturovanosti – opakovaně utvářet. To platí jak na úrovni gramatické, tak na úrovni lexikální. Osvojování slovotvorby představuje v tomto kontextu jednu z prvních oblastí, ve které můžeme takové ovládnutí produktivní povahy jazyka pozorovat. Fascinující nárůst bohatství slovní zásoby u dětí[1] je zřejmě do jisté míry možný také proto, že děti jsou často již před koncem druhého roku života schopny utvářet nová slova na [147]základě aktivního užití slovotvorných postupů (srov. přehled u Clarkové, 1995). Je přitom zřejmé, že faktorů, které ovlivňují počáteční dobu tohoto osvojení, snadnost celého procesu a také dětské slovotvorné preference, je hned několik. Patří k nim jak míra produktivity slovotvorných postupů v daném jazyce, tak např. přítomnost slovotvorně utvářených jednotek v řečovém inputu apod. Většina hypotéz o těchto mechanismech však byla dosud formulována na pozadí výzkumu angličtiny a jí typologicky blízkých jazyků. Podrobnou analýzu zapojených mechanismů a faktograficky bohatější popis průběhu osvojování slovotvorby ve slovanských jazycích, češtinu nevyjímaje, prozatím postrádáme.[2] Naším cílem bylo proto ověřit, jak zobecnitelná jsou některá dosavadní zjištění z jiných jazyků, a zároveň získat pro češtinu první systematičtější empirická data z oblasti osvojování slovotvorby. Zaměřili jsme se na problematiku osvojování kompozit, která představují v systému češtiny sice méně produktivní, nicméně i tak poměrně bohatě strukturovanou kategorii.[3]
Obecná struktura hypotézy
Jak bylo naznačeno výše, je poměrně běžným předpokladem, že při raném osvojování jazyka si děti nejprve osvojují neanalyzované komunikační jednotky a teprve později jsou (pravděpodobně na základě analogického porovnávání) schopny rozpoznat jejich vnitřní strukturu a osvojit si tak i menší jazykové jednotky samostatně se nevyskytující. S tímto předpokladem pracuje např. i významná iniciační studie Berkové (Berko, 1958) zkoumající prostřednictvím úkolů s pseudoslovy osvojování anglických flektivních a derivačních morfémů; ve vztahu k osvojování hlásek o tom zase hovoří např. Clarková ve své přehledové práci o osvojování jazyka (Clark, 2009, s. 112).
Kompozita představují v tomto ohledu specifickou skupinu jazykových jednotek s vnitřní strukturou: jejich stavba, soustředíme-li se na stavbu slovotvornou, neobsahuje nutně jednotky samostatně se nevyskytující. Platí to především v izolačních jazycích (např. angličtině), v nichž jako konstituenty vstupují do kompozit v podstatě celá slova a není mezi ně vkládán žádný konektém (viz např. blackboard tabule, raincoat pláštěnka, chocolate cake čokoládový dort), „kompozita“ se tak mnohdy od syntaktického spojení liší pouze přízvukem[4] (slovní přízvuk na druhém konstituentu je – v angličtině – redukovaný[5]). Ve prospěch představy o počátečním osvojování kompozit bez analýzy vnitřní struktury však hovoří fakt, že některá z nich se mohou v paměti mluvčího uchovávat bez [148]vědomí vnitřní struktury i v pozdějším dětství nebo i v dospělosti (a to právě i v izolačních jazycích)[6]. A hovoří pro něj i výsledky studie autorek Krottové a Nicoladisové (2005), které testovaly hypotézu vycházející právě z předpokladu, že i kompozita jsou původně osvojována neanalyzovaně. Studie přinesla data ukazující, že anglickým dětem se daří lépe identifikovat konstituenty kompozit (angl. compounds), jedná-li se o konstituenty, které jsou sdílené více různými kompozity. Zná-li tedy dítě více různých kompozit obsahujících konstituent chocolate (např. chocolate bar, chocolate candy, chocolate cookie, chocolate milk, …), je pravděpodobnější, že si tohoto konstituentu povšimne a rozpozná tato slova jako složená, než v případě, kdy zná takových kompozit jen málo (např. birthday). Tento vzorec, který nalezly ve svých datech, nazývají autorky efektem velikosti (kompozitní) rodiny (angl. effect of constituent family size). Odpovídající výsledek pak autorky při stejné metodice nalezly i v následné studii provedené na francouzštině (s bilingvními kanadskými dětmi; viz Nicoladis – Krott, 2007). Efekt velikosti kompozitní rodiny se tak zdá být jedním z oněch hledaných mechanismů, které řídí proces slovotvorného osvojování. Podle těchto výsledků se zdá smysluplný i původní předpoklad o neanalyzovaném osvojování.
„Na základě efektu velikosti rodiny, který se projevil v našem experimentu, usuzujeme, že rozpoznání vnitřní struktury je posilováno znalostí různých dalších kompozit sdílejících s cílovým kompozitem modifikační (a řídící) konstituent. Domníváme se tedy, že členy rodiny jsou propojeny a spoluaktivovány podobným způsobem, jaký se ukazuje ve studiích s dospělými subjekty.“ (Krott – Nicoladis, 2005, s. 156)[7]
Jednou ze studií s dospělými subjekty, na něž autorky v citaci odkazují, je i de Jong et al. (2002), která se zabývala reakčními časy v úloze detekce slova, v níž měly testované osoby rychle odpovídat, zda sekvence, kterou vidí na obrazovce, je existující konvenční (anglické/holandské) kompozitum, nebo není. Výsledky tohoto výzkumu nejsou, pokud jde o výskyt efektu velikosti rodiny při mentálním zpracování kompozit, jednoznačné[8], nicméně autorky Krottová s Nicoladisovou odkazují na pozitivní výsledek v případě anglických kompozit psaných zvlášť. Zde se efekt velikosti rodiny – ve smyslu rychlejších reakcí na kompozita patřící do velkých rodin – objevil.
Tváří v tvář této evidenci Krottová s Nicoladisovou uvádějí, že jejich záměrem je zkoumat, jak postupný nárůst znalosti slovotvorně motivovaných slov (v angl. morphologically complex words) vede ke změnám reprezentace těchto slov, ke vzniku vazeb mezi osvojenými slovy na základě jejich podobné vnitřní [149]morfologické stavby (viz Krott – Nicoladis, 2005, s. 141 a 156). Takto nahlížený výzkum osvojování kompozit, jejich vnitřní struktury a ovlivňujících faktorů tedy zapadá svou povahou do širšího kontextu výzkumu mentálního lexikonu. Ten je v něm vnímán jako síť lexikálních hesel s vnitřními vztahy, které se v průběhu osvojování jazyka postupně v dětské mysli ustavují. Naším záměrem bylo na typologicky odlišném jazyce (na češtině) ověřit zjištění studie Krott – Nicoladis (2005), popřípadě zachytit možné rozdíly, které by mohly vyplývat z odlišných strukturních vlastností obou jazyků, a přispět tak do debaty o možné jazykové specifičnosti mechanismů řídících fungování mentálního lexikonu.
2 Metoda
2.1 Procedura
Rozhovory s dětmi
Identifikaci konstituentů jsme u dětí zjišťovali prostřednictvím řízeného rozhovoru. Administrátor hovořil s každým dítětem samostatně a rozhovor trval vždy asi pět minut. Počáteční instrukce zněla přibližně následovně:
Budeme hrát hru s Johankou (jméno pro panenku používanou – ve většině případů – pro usnadnění kontaktu s dítětem), ona se nás bude ptát na slova, která slyšela, ví, co znamenají, ale zajímá ji, proč se říkají zrovna takhle. Nejdřív to zkusím já, abys viděl/a, jak se to bude hrát, a potom už to zkusíš ty. Johanka se mě ptala třeba na slovo nosorožec. Proč se nosorožci říká zrovna nosorožec? Tak jsem jí to zkusila vysvětlit tak, že je to zvíře, které má na nose roh. A pak slyšela slovo černokněžník. Zkusíš jí vysvětlit, proč se černokněžníkovi říká zrovna černokněžník?
Dítě takto odpovídalo na 21 kompozit. Rozhovor byl nahráván na diktafon pro následný přepis a skórování.
Dotazníky pro dospělé
Součástí výzkumu byla také dvě dotazníková šetření mezi dospělými, na jejichž základě byla posléze částečně upravena sada cílových kompozit. Jednalo se nejprve o škálové hodnocení transparentnosti těchto kompozit a posléze u dospělých proběhla i obdobná úloha jako u dětí, pouze v písemné formě a se zjednodušenou instrukcí, za níž následoval seznam kompozit:
Odpovězte prosím co nejstručněji na otázku, proč se dané věci říká zrovna tak, jak se jí říká. (Proč se horolezci říká zrovna horolezec? / Proč se kolotoči říká zrovna kolotoč? atd.)
Na základě těchto dotazníků[9] s dospělými respondenty jsme vyřadili z cílové sady slovo dobrovolník, které se jevilo příliš netransparentní (do analýzy jsme tedy nakonec zařadili pouze 20 kompozit, viz zde poznámka č. 3).
[150]Rodičovský dotazník (RD)
Pro přípravu sady cílových kompozit jsme při vyvažování počtu zastoupených konstituentů s malou a velkou rodinou vycházeli z údajů ve Frekvenčním slovníku češtiny (Čermák – Křen, 2004), nicméně pro analýzu jsme poté primárně používali údaje získané prostřednictvím rodičovských dotazníků. Dotazníky měly podobu seznamů (cílových kompozit, jejich motivujících slov a dalších kompozit z jejich rodin), z nich rodiče vybírali a označovali slova, o nichž by řekli, že je jejich dítě zná. Instrukce zněla:
Zakroužkujte prosím ta slova, která by Vaše dítě samo spontánně použilo nebo o kterých jste si jisti, že jim rozumí. (I taková slova, která by použilo s odlišným významem, než je běžné u dospělých.)
Na základě vyplněných rodičovských dotazníků jsme pak spočítali průměrný počet členů rodin pro jednotlivé konstituenty v rámci našeho vzorku čtyřiatřiceti dětí a získali jsme tak vedle korpusové velikosti rodiny (korpusová VR) ještě individuální velikost rodiny (IVR).
Pro účely statistické analýzy jsme rozdělili cílové položky na konstituenty s malou rodinou a s velkou rodinou: na základě korpusové VR byla hranice stanovena na základě mediánu (Me=4) mezi třemi a čtyřmi členy; na základě průměrné IVR pak byl hranicí jeden celý člen, tzn. do skupiny s malou IVR spadaly konstituenty, jejichž průměrná IVR nedosáhla ani jednoho členu[10]. Zařazení konstituentů do skupiny s malou a velkou rodinou se podle těchto dvou kritérií částečně lišilo: čtyři konstituenty patřily podle kritéria korpusová VR do skupiny s malou rodinou, ale podle kritéria individuální VR do skupiny s velkou rodinou a sedm jiných konstituentů naopak. Přesné údaje jsou uvedeny v tabulce 1.
Ke kategoriálnímu rozdělení do skupin jsme přistoupili především proto, aby naše studie zachovala postupy užité ve studii Krott – Nicoladis (2005) a jejich výsledky tak byly srovnatelné. Principiálně to však není nutné. Je možné analyzovat jak korpusovou VR, tak individuální VR jako numerické proměnné, tj. jako přesný (resp. průměrný) počet členů v rodině. V sekci Výsledky se budeme věnovat jak analýze kategoriální, tak numerické.
Rodičovský dotazník také poskytl údaje (rodičovské odhady) o obeznámenosti dětí s motivujícími slovy cílových kompozit. Tato data zobrazuje tabulka 2.
Obrázkový test
Pro informaci o tom, zda děti znají vybraná cílová kompozita, jsme použili obrázkový test, v němž dítě ze tří možností vybíralo, na kterém obrázku je cílové kompozitum. Test se realizoval jeden až tři týdny před samotným rozhovorem
| korpusová VR | |||||
|
| malá | průměrná IVR |
| velká | průměrná IVR |
| lapka | 1 | 0,29 | věda | 4 | 0,32 |
| rubec | 1 | 0,47 | vláska | 5 | 1,65 |
| kněžník | 1 | 0,41 | země- | 5 | 1,06 |
| zvyk | 1 | 0,12 | zlato- | 6 | 1,21 |
| manželé | 1 | 0,24 | teplo- | 6 | 1,12 |
| ostrov | 1 | 0,24 | plno- | 7 | 0,5 |
| vous | 1 | 0,29 | měr | 9 | 1,5 |
| lepka | 1 | 0,76 | dřevo- | 10 | 0,56 |
| cvik | 1 | 0,71 | vysoko- | 11 | 0,32 |
| hled | 2 | 0,97 | zlo- | 11 | 1,74 |
| chvála | 2 | 0,15 | vodo- | 12 | 2,32 |
| přírodo- | 2 | 0,21 | černo- | 13 | 2,59 |
| město | 2 | 0,35 | vod | 15 | 0,71 |
| tělo- | 2 | 0,74 | pis | 22 | 1,15 |
| mucho- | 2 | 1,18 | novo- | 24 | 0,74 |
| vedoucí | 3 | 0,65 | velko- | 35 | 0,71 |
| stroj(o)- | 3 | 0,91 | samo- | 37 | 2,21 |
| školák | 3 | 0,59 | polo- | 42 | 3,62 |
| toč | 3 | 1,32 | sebe- | 47 | 1,06 |
| daleko- | 3 | 1,12 | kolo- | 3 | 2,35 |
Tab. 1 Korpusová a individuální velikost rodiny konstituentů
|
|
| obeznámenost dětí |
|
| obeznámenost dětí | ||
|
|
| počet | % |
|
| počet | % |
| -lapka | lapat | 0 | 0 | -město | město | 30 | 88,2 |
| -rubec | rubat | 0 | 0 | země- | země | 30 | 88,2 |
| -kněžník | kněz | 2 | 5,9 | -vous | vous(y) | 31 | 91,2 |
| -věda | věda | 5 | 14,7 | tělo- | tělo | 31 | 91,2 |
| -vedoucí | vedoucí | 6 | 17,6 | -školák | škola | 32 | 94,1 |
| -zvyk | zvyk | 7 | 20,6 | -lepka | lepit | 32 | 94,1 |
| -hled | hledět | 11 | 32,4 | -toč | točit | 32 | 94,1 |
| sebe- | sebe | 12 | 35,3 | dřevo- | dřevo | 33 | 97,1 |
| -chvála | chvála | 15 | 44,1 | -cvik | cvičit | 33 | 97,1 |
| -manželé | manželé | 18 | 52,9 | velko- | velký | 33 | 97,1 |
| polo- | poloviční | 19 | 55,9 | -pis | psát | 33 | 97,1 |
| plno- | plný | 21 | 61,8 | zlo- | zlý | 33 | 97,1 |
| -vod | vést | 24 | 70,6 | samo- | sám | 33 | 97,1 |
| stroj(o)- | stroj | 24 | 70,6 | vodo- | voda | 33 | 97,1 |
| -vláska | vlas(y) | 24 | 70,6 | černo- | černý | 33 | 97,1 |
| zlato- | zlatý | 25 | 73,5 | novo- | nový | 34 | 100 |
| přírodo- | příroda | 28 | 82,4 | daleko- | daleko | 34 | 100 |
| -ostrov | ostrov | 28 | 82,4 | teplo- | teplo | 34 | 100 |
| -měr | měřit | 28 | 82,4 | mucho- | moucha | 34 | 100 |
| vysoko- | vysoký | 29 | 85,3 | kolo- | kolo | 34 | 100 |
Tab. 2 Obeznámenost dětí s motivujícími slovy cílových kompozit: kolik / jaké procento rodičů uvedlo, že jejich dítě slovo zná
|
|
| obeznámenost dětí | |||
|
| počet | % |
| počet | % |
| přírodověda | 20 | 58,8 | vodovod | 31 | 91,2 |
| vysokoškolák | 23 | 67,6 | černokněžník | 32 | 94,1 |
| zlozvyk | 27 | 79,4 | velkoměsto | 32 | 94,1 |
| strojvedoucí | 29 | 85,3 | dřevorubec | 33 | 97,1 |
| dalekohled | 30 | 88,2 | plnovous | 33 | 97,1 |
| tělocvik | 30 | 88,2 | poloostrov | 33 | 97,1 |
| zeměpis | 30 | 88,2 | kolotoč | 34 | 100 |
| mucholapka | 31 | 91,2 | teploměr | 34 | 100 |
| novomanželé | 31 | 91,2 | zlatovláska | 34 | 100 |
Tab. 3 Počet/procento dětí, které v obrázkovém testu správně identifikovaly cílová kompozita
zjišťujícím uvědomění slovotvorné motivace. Výsledky tohoto testu prezentuje tabulka 3. Přes poměrně vysoký výsledek pro slova zlozvyk, zeměpis a mucholapka byla tato slova pojímána spíše jako dětem neznámá. Při následném rozboru po realizaci testu i rozhovoru se totiž ukázalo, že v případě těchto položek byl výsledek obrázkového testu poněkud zkreslený tím, že děti podle cílového obrázku identifikovaly pouze první člen kompozita, nikoli celé kompozitum (moucha na obrázku představujícím mucholapku; globus na obrázku představujícím zeměpis; mračící se žena, která se zlobí na obrázku představujícím zlozvyk). Do testu nebyla zahrnuta slova sebechvála a samolepka z důvodu jejich obtížného vizuálního ztvárnění (obrázky byly vytvářeny speciálně pro tuto studii).
2.2 Jazykový materiál
Každé dítě zodpovídalo otázky na slovotvornou motivaci 21 kompozit, do analýzy bylo (po vyřazení dobrovolníka) zařazeno 20 kompozit. Cílovou sadu předkládáme v tabulce 4. Kompozita byla vybírána s ohledem na tři faktory: velikost rodiny konstituentů, konkrétnost a motivační transparentnost, tj. slova měla být pro průměrného dospělého mluvčího slovotvorně zřetelná (viz oddíl Dotazníky pro dospělé).
Z hlediska slovotvorné a onomaziologické stavby se jedná o determinační substantivní kompozita a jedno juxtapozitum (sebechvála). Zařazena jsou jak kompozita čistá, kde dochází ke skládání onomaziologické báze a příznaku (velk-o-město; pol-o-ostrov), tak smíšená, kde dochází ke skládání dvou složek onomaziologického příznaku a navíc k dalšímu slovotvornému postupu – derivaci či konverzi sloužící k vyjádření onomaziologické báze (čern-o-kněž-ník; kol-o-toč-Ø).[11] Druhý typ (smíšená kompozita, v anglické terminologii se jim [153]blíží tzv. synthetic compounds) byl v anglické studii eliminován a cílová sada byla z hlediska slovotvorné struktury celkově homogennější (jednalo se o slova motivovaná pouze substantivy). Vzhledem k menšímu počtu a frekvenci kompozit v češtině jsme v našem případě přistoupili na heterogennější výběr.
| černokněžník | velkoměsto | vysokoškolák | strojvedoucí |
| plnovous | přírodověda | kolotoč | zlatovláska |
| teploměr | vodovod | sebechvála | novomanželé |
| dalekohled | dřevorubec | zeměpis | tělocvik |
| poloostrov | samolepka | mucholapka | zlozvyk |
Tab. 4 Seznam cílových kompozit
2.3 Skórování
Odpovědi dětí na otázky „proč se říká“ byly skórovány 0 – 1 – 2 body. Každý konstituent byl skórován samostatně. Dva body byly uděleny v případě, že v odpovědi v nějaké podobě zazněl kořen daného konstituentu.
| Proč se černokněžníkovi říká zrovna černokněžník? |
| |
|
| Protože má černej kabát? (id39; M; 6;2)[12] | 2/0 |
| Proč se mucholapce říká zrovna mucholapka? |
| |
|
| Protože se do ní… lapí vlastně mouchy. (id26; F; 5;5) | 2/2 |
| Proč se strojvedoucímu říká zrovna strojvedoucí? |
| |
|
| Protože vede. (id35; F; 3;9) | 0/2 |
Dva body byly rovněž uděleny v případě kompozita plnovous při použití synonyma tolik/hodně/moc k vyjádření významu plno. Jistá tendence k synonymnímu vyjádření byla v tomto případě totiž zaznamenána i u dospělých respondentů (8 z 27 dotazovaných použilo opisy mnoho/dlouhý/celý/zarostlý atd.)
| Proč se plnovousu říká zrovna plnovous? |
| |
|
| Protože je moc toho vousu. (id30; F; 5;8) | 2/2 |
Výjimkou, při níž nezazněl kořen konstituentu, a přesto byla odpověď skórována více než nulou, byly (kromě konstituentu plno- v plnovousu) také případy odpovědí na čistá kompozita, v nichž docházelo k elipse subjektu a nezazněl v nich druhý člen. V těchto případech jsme udělovali po jednom bodu. Podrobněji se k těmto případům vrátíme v Diskusi.
| Proč se poloostrovu říká zrovna poloostrov? |
| |
|
| Protože je jenom poloviční. (id32; M; 5;11) | 2/1 |
Nulou byly oskórovány všechny ostatní případy. Kromě výše uvedených příkladů (1) a (3) a jim podobných šlo i o množství odpovědí, které se ani neblí[154]žily ideální představě o vysvětlení slovotvorné motivace (viz příklady 6–7). Nulou byly rovněž oskórovány odpovědi nevím nebo mlčení, kterých bylo v našem datovém korpusu 15 %, tj. 101 odpovědí nevím nebo mlčení z celkových 680 odpovědí.
| Proč se vodovodu říká zrovna vodovod? |
| |
|
| Protože to je nějakej kohoutek. (id35; F; 3;9) | 0/0 |
| Proč se poloostrovu říká zrovna poloostrov? |
| |
|
| Protože tam jsou palmy. (id44; M; 4;10) | 0/0 |
Dětské odpovědi byly tímto způsobem skórovány třemi, resp. dvěma hodnotiteli[13], jejichž mezihodnotitelská shoda (při skórování na základě popsaných kritérií) byla poměrně vysoká (n=982, procento shody 99,8 %, k=0,996 (Cohenova kappa)). Jediná neshoda panovala v případě dvou odpovědí na kompozitum zlozvyk, v nichž zazněl tvar zlobí (se). Nakonec jsme se přiklonili ke striktnímu uplatnění pravidla výskytu motivujícího slovního kořenu a odpovědi jsme skórovali dvěma body za konstituent zlo-.
2.4 Účastníci
Do analýzy byla zařazena data od 34 dětí ze tří mateřských škol v Olomouci, Praze a Sebranicích u Boskovic. Z původně zamýšleného vzorku byly některé subjekty vyřazeny především z důvodu rodičovského nesouhlasu, resp. nevyplnění (časově poměrně náročného) dotazníku. Tato studie zpracovává pouze data od dětí, jejichž rodiče poskytli informovaný souhlas s účastí ve výzkumu i se zpracováním dat.
Jeden z rodičovských dotazníků uváděl, že rodiče s dítětem mluví kromě češtiny také ukrajinsky; jiný uváděl jako druhý jazyk angličtinu. Data těchto dětí jsme ve vzorku ponechali, protože nevykazovala žádné rozdíly v porovnání s ostatními dětmi vyrůstajícími pouze s jedním jazykem.
Děti byly ve věku od 3;1 do 6;10 (průměr 4;10), dívek bylo 16, s průměrným věkem 4;8, a chlapců 18, s průměrným věkem 5;1.
3 Výsledky
Naším cílem bylo testovat vliv velikosti kompozitní rodiny konstituentu na dětskou schopnost identifikovat tyto konstituenty (a motivující slova / kořeny kompozit). Jako měřítko identifikace konstituentu jsme zvolili skóre udělované za dětské odpovědi na otázku „proč se věci X říká zrovna X?“ Kromě proměnné [155]velikost rodiny jsme však testovali ještě množství dalších proměnných přicházejících v úvahu jako faktory ovlivňující to, jak se dítěti v dané úloze povede.
Statistická analýza
Statistické výpočty byly provedeny v programu R (http://www.r-project.org/). Hladina statistické významnosti byla u všech testů stanovena na 5 %. Rozdíly v hodnotách spojitých proměnných mezi dvěma skupinami pozorování byly posuzovány prostřednictvím parametrického Studentova t-testu (případně parametrického Welchova testu, pokud byla F-testem zamítnuta shoda rozptylů výběrů), resp. neparametrického Mannova-Whitneyova testu v závislosti na výsledcích testů normality dat (posuzováno Shapirovým-Wilkovým testem normality). Míra korelace spojitých veličin byla hodnocena pomocí Spearmanova korelačního koeficientu spolu s testováním jeho statistické významnosti.
Výpočet mezihodnotitelské shody byl proveden prostřednictvím webového kalkulátoru ReCal2 (přístupného z <http://dfreelon.org/utils/recalfront/>).
Statisticky významné výsledky v textu označujeme hvězdičkou.
Proměnné podle dětí
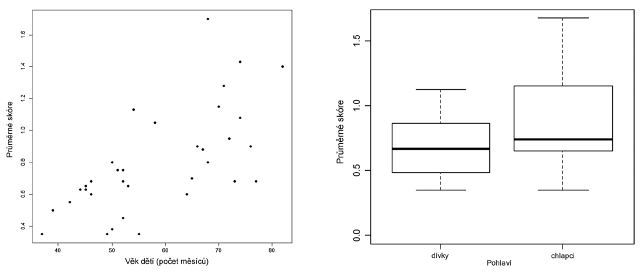
Za významný faktor v testové situaci lze spolehlivě považovat věk dítěte. Čím je dítě starší, tím lépe se mu daří identifikovat konstituenty, resp. tím častěji formuluje svou odpověď na zadanou otázku s použitím motivujících kořenů. Spearmanův korelační koeficient pro vztah mezi věkem dětí v našem vzorku a jejich skóre dosahuje poměrně vysoké hodnoty (n=34, rs=0,7, p<0,001*). Tento vztah je znázorněn v grafu č. 1.
Jako další možný faktor z hlediska vlastností dětí se nabízí pohlaví. Průměrné skóre pro chlapce a dívky z našeho vzorku uvádíme v grafu č. 2. Na 5% hladině není na základě statistického testu rozdíl mezi skóre dívek a chlapců statisticky významný (Studentův dvouvýběrový t-test, t(32)=-2,02, p=0,052), nicméně výsledek testu přesahuje 5% hladinu jen nepatrně. Analýza kovariance (kde bylo jako závislá proměnná použito skóre, jako hlavní faktor pohlaví a jako doprovodná nezávislá proměnná věk) ukázala, že po očištění od vlivu věku nemá pohlaví na výši dosaženého skóre vliv (ANCOVA, F(1,31)=3,29, p=0,08).
Proměnné podle konstituentů
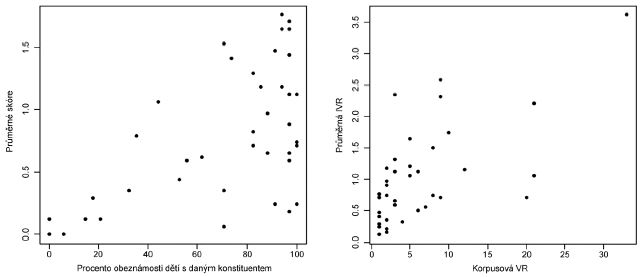
Obeznámenost s konstituentem: Významným nejazykovým faktorem ovlivňujícím dětskou úspěšnost v naší testové situaci je rovněž obeznámenost dětí s motivujícími slovy cílových kompozit. Konstituenty, jejichž motivující slova zná vyšší procento dětí z našeho vzorku, získávaly rovněž vyšší průměrné skóre. Tento vztah jsme ověřovali opět pomocí Spearmanova korelačního koeficientu (n=40, rs=0,47, p<0,05*) a je znázorněn v grafu č. 3.
|
| |
| Graf 1 Průměrné skóre dětí podle věku (n=34) | Graf 2 Průměrné skóre dětí podle pohlaví (n=34) |
Velikost rodiny: Mezi nezávislými proměnnými korpusová VR a individuální VR jsme podle očekávání zaznamenali pozitivní korelaci, Spearmanův korelační koeficient je statisticky významně odlišný od nuly (n=40, rs=0,58, p<0,001*). Vztah mezi nimi znázorňuje graf č. 4. Korelace nicméně není stoprocentní (viz i tabulka 1) a mohli bychom očekávat, že vztah těchto proměnných k úspěšnosti dětí nebude úplně analogický, např. že individuální VR bude lépe vystihovat skutečnou jazykovou reprezentaci dětí. Ani jedno z těchto dvou numerických vyjádření hlavní sledované proměnné velikost rodiny konstituentu však nevykazuje při korelační analýze statisticky významný vliv na průměrné skóre konstituentů[14].
Analýzy ukázaly, že silně proti očekávanému efektu rodiny jsou naše data ovlivňována položkami samo- a -lepka. Mezi skupinami s malou a velkou IVR (tj. pro proměnnou IVR v kategorizovaném vyjádření) jsme na základě statistického testu prokázali na hladině 5 % významný rozdíl ve skóre pouze pro vzorek bez slova samolepka (Studentův t-test, t(36)=-2,29, p<0,05*). Průměrné skóre v závislosti na kategorizované IVR v tomto zmenšeném vzorku je uvedeno v grafu č. 5. Nicméně nahlížíme-li na proměnnou IVR jako na průměrný počet členů v rodině, nikoli jako na kategorie malá a velká, nenacházíme ani ve zmenšeném vzorku statisticky významnou pozitivní závislost mezi IVR a výší skóre (test významnosti Spearmanova korelačního koeficientu, n=38, rs=0,27, p=0,10).
Pozice konstituentu: V našich datech jsme nezaznamenali významný rozdíl ve skóre za modifikační (první) a řídící (druhé) konstituenty: W=218, p=0,64
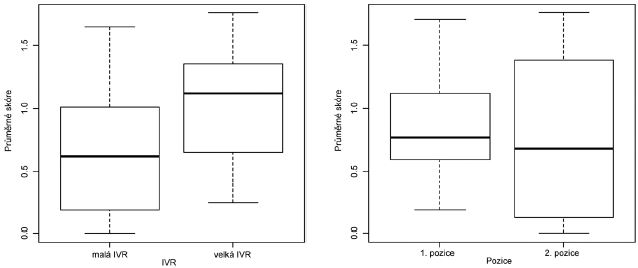
(Mann-Whitneyův test), průměrné skóre konstituentu podle pozice v kompozitu je uvedeno v grafu č. 6. Zmiňujeme se o tom proto, že ve výsledcích Krottové s Nicoladisovou takový rozdíl byl a autorky jeho interpretaci věnují hodně pozornosti – podrobněji se k této otázce vrátíme v diskusi.
Slovotvorná struktura: Rovněž jsme nezaznamenali významný rozdíl ve skupinách konstituentů rozdělených podle slovotvorného postupu v kompozitu ani podle slovního druhu motivujícího slova. Tj. v rámci našeho vzorku nebyl vý[158]znamný rozdíl v tom, zda děti odpovídaly na čistá, nebo na smíšená kompozita (W=168,5, p=0,71), ani v tom, zda odpovídaly na kompozitum se slovesným motivujícím slovem, nebo bez (W=223, p=0,54). Přesto nelze vyloučit, že naše cílová sada je příliš heterogenní (např. ještě v jiných aspektech, jichž si nejsme vědomi) a že rozdíl daný jmenovanými proměnnými ve skutečnosti existuje.
4 Diskuse
Kompozitum vs. fráze
Na rozdíl od anglické studie autorek Krottové a Nicoladisové (2005) neprokázala výše popsaná analýza českých dat příliš spolehlivě přítomnost efektu velikosti rodiny v úloze, v níž mají předškolní děti vysvětlovat slovotvornou motivaci kompozit. Je možné, že odlišné vyznění obdobné analýzy na angličtině a na češtině je způsobeno typologickými strukturními rozdíly, jak jsme naznačili již v úvodu. V literatuře (viz Matthews, 1991 a Aikhenvald, 2007) jsou vymezována kritéria pro rozlišení „kompozit“ a syntaktických frází napříč jazyky, na základě kterých lze vidět zřetelné analogie mezi českými kompozity a anglickými compounds. Jedná se o následující kritéria (primárně vycházíme z třídění podle Matthewse, 1991, s. 93–100):
a) morfologické: První konstituent kompozita je nesamostatný morfém a nepřijímá flektivní afixy. V angličtině je toto kritérium spíše okrajové. V češtině je morfologické kritérium natolik silné, že otázka odlišování kompozit od frází ani nebývá nastolována. Přesto nelze tvrdit, že by bylo stoprocentně platné – srov. např. stroj-vedoucí a kategorii juxtapozice.
b) sémantické: Význam kompozita není pouhým součtem významů jeho konstituentů.
c) morfosyntaktické: Konstituenty kompozita není možné v proudu řeči oddělit dalším slovem nebo morfémem.
d) fonologické: Hlavní přízvuk v kompozitu je nesen prvním členem.
Matthews nicméně rovněž zdůrazňuje (viz tamtéž s. 100) škálový charakter přechodů mezi frázemi a kompozity daný plynulým vývojem jazyka, což zmiňuje i Dokulil při analýze strukturní situace v češtině (1967, s. 22 a 39). Načrtneme-li následující schéma vycházející z české terminologie, můžeme tak nahlédnout i do rozdílů, které spočívají společně a neoddělitelně ve strukturních rozdílech obou jazyků i v odlišné tradici lingvistické deskripce:
syntagma (fráze) → juxtapozice → přechodné typy[15] → vlastní kompozice.
Na základě srovnání anglických (kromě zmiňovaného Matthewse viz např. Bauer, 1983 nebo Dressler, 2007) a českých (Dokulil, 1967 a Bozděchová, 1995) slovotvorných popisů je možné říct, že v anglické lingvistice se jedná primárně [159]o rozdíl sémanticko-fonologický, a tak je podle nás již za první šipkou přechod od frází ke compounds, zatímco v české lingvistice je přechod ke kompozitům lokalizován až za druhou nebo třetí šipku a jedná se primárně o rozdíl morfologický.
Ze studie de Jong et al. (2002) vyplývá (viz Úvod), že efekt velikosti kompozitní rodiny se v jejich výzkumu projevil pouze u kompozit, která mohou na naznačené škále mít stále ještě blíže k frázím (anglická kompozita psaná zvlášť), a nikoliv u kompozit ustálenějších jako jednoslovná pojmenování (anglická psaná dohromady a holandská). Jsou-li pojmenování jako grapefruit juice nebo chocolate cake pojímána jako compounds, může se jednat spíše o úzus lingvistické deskripce a tento jev nemusí být stejným způsobem mentálně reprezentován. Mentální reprezentace se může blížit spíše situaci, kdy cake je jednou z frekventovaných kolokací slova chocolate a společně s dalšími tvoří jeho rodinu, nicméně ne kompozitní, ale kolokační. Naopak slova jako blackboard nebo raincoat (resp. česká teploměr, kolotoč atd.) mohou mít natolik sjednocenou reprezentaci, že již nepodléhá stejným principům jako předchozí a efekt rodiny zde nemusí figurovat. V případě českých (silně lexikalizovaných) kompozit tak může být nepřítomnost efektu velikosti rodiny v souladu s výsledky obou předchozích studií.
Efekt pozice
Významným rozdílem ve výsledcích oproti anglické studii byla pro nás rovněž nepřítomnost efektu pozice konstituentu. Autorky Krottová s Nicoladisovou uvádějí, že děti v jejich vzorku statisticky významně častěji zmiňovaly ve svých odpovědích první – modifikační – konstituent, z toho důvodu dosahovaly první konstituenty v průměru vyššího skóre. V našem výzkumu jsme rozdíl mezi výší skóre modifikačních a řídících konstituentů nezaznamenali. Domníváme se, že hlavní důvod spočívá v našem zařazení smíšených kompozit do cílové sady (viz oddíl 2.2 Jazykový materiál). Krottová s Nicoladisovou (2005, s. 147) k tomu uvádí:
„Toto nízké skóre pro řídící konstituenty má přinejmenším dva možné důvody. Zaprvé, jak už jsme zmiňovali, podle rodičovských dotazníků byly řídící konstituenty méně známé (76 %) než modifikační (85 %). Zadruhé děti k řídícímu konstituentu často odkazovaly zájmenem it jako např. v odpovědi ‘because there is cheese in it’ při vysvětlování motivace cheese sandwich. Protože v takovém případě není řídící konstituent zmíněn, skórovali jsme ho nulou.“
Anglická studie pracovala pouze s tzv. root compounds, tj. z hlediska české terminologie pouze s čistými kompozity. Výše jsme uváděli, jak se čistá a smíšená kompozita liší v onomaziologické stavbě. U čistých kompozit se ‚syntaktická‘ analýza na řídící a modifikační člen překrývá s onomaziologickou analýzou [160]na bázi a příznak; u smíšených tomu tak není – na řídící a modifikační člen tu rozkládáme pouze (dvousložkový) příznak:
velk-o-město
báze = město → řídící konstituent -město
příznak = je velké → modifikační konstituent velk(o)-
zlat-o-vlás-ka
báze = nositel vlastnosti → sufix -k(a)
příznak = má zlaté vlasy → oba konstituenty zlat(o)- a -vlás-
Důležité proto podle nás není, že dítě nezmiňuje řídící konstituent, nýbrž že nezmiňuje onomaziologickou bázi. Z tohoto pohledu jsou pak následující odpovědi analogické:
| Proč se velkoměstu říká zrovna velkoměsto? | |
|
| Protože je veliké. (id2; F; 6;1) |
| Proč se zlatovlásce říká zrovna zlatovláska? | |
|
| Protože má zlatý vlasy. (id11; M; 3;10) |
V odpovědi (8) je lexikálně vyjádřen pouze příznak, a protože jde o čisté kompozitum, chybí v ní vyjádření řídícího konstituentu. V odpovědi (9) je rovněž vyjádřen pouze příznak, ale protože jde o smíšené kompozitum, jsou zároveň vyjádřeny oba konstituenty.
Krottová s Nicoladisovou vysvětlují častější přímé zmiňování modifikačního konstituentu jeho specifikující sémantickou rolí v kompozitu, jehož funkci je možné popsat jako subkategorizační. V subkategorizačním kontextu je podle nich specifikující složka důležitější než složka specifikovaná („… modifikátor, tedy konstituent, který vyjadřuje rozlišovací rys, se může stát důležitějším než hlava.“, Krott – Nicoladis, 2005, s. 155). Domníváme se, že specifikující role onomaziologického příznaku (resp. modifikačního konstituentu) je velmi podstatná, nicméně vysvětlení, že tato složka je (významově) důležitější než složka specifikovaná, podle nás není dostačující. Protože specifikující složka kompozita svým způsobem zastává v daném kontextu pozici nové informace (navíc nese slovní přízvuk) zasluhující si vysvětlení, zatímco specifikovaná složka zůstává v pozadí jako informace zřejmá a známá, je podle nás potřeba v rámci dialogického kontextu použité metody počítat s jevy souvisejícími s tematicko-rematickou výstavbou textu, tj. s anaforickým odkazováním a elipsou subjektu.
Kompozitum samolepka
Zajímavým výsledkem naší studie je, že při vyřazení slova samolepka se v analýze kategoriální proměnné IVR efekt rodiny přece jen projevil. Čím je slovo samolepka mezi všemi ostatními specifické? Nezdá se, že by bylo snadné nalézt na tuto otázku odpověď. Mezi cílovými kompozity není ani jediné se slo[161]vesným motivátorem (vodovod, teploměr atd.), ani jediné se zájmenným motivátorem (sebechvála), což jsou slovní druhy, u nichž bychom mohli při osvojování jazyka očekávat větší obtíže (ohledně problémů s anglickými slovesnými kompozity v produkci viz Clark, 1995, s. 150). Bližší pohled na cílovou sadu a na možné důvody, proč děti spíše nezmiňují konstituent samo-, i když má velkou rodinu (ale zmiňují sebe-), zato zmiňují konstituent -lepka, i když má malou rodinu, nás může dovést k tomu, že sloveso lepit, přestože jeho kompozitní konstituent -lepka má malou rodinu (vytváří jen jediné kompozitum), je dětem samo o sobě dostatečně známé, aby ho v kompozitu rozeznaly.
Je také možné, že celá sada, byť vybíraná pečlivě s ohledem na velikost rodiny konstituentů, s ohledem na použití minima abstraktních slov a maxima slov známých dětem z jejich nejbližšího okolí i s ohledem na transparentnost slovotvorné motivace, je příliš heterogenní na podobná zobecnění, čímž jsme se částečně zabývali již v oddíle 2.2 Jazykový materiál.
Slovotvorná motivace vs. popis referentu
Jako zajímavá možnost se jeví, zda dětskou analýzu kompozit neovlivňuje např. syntakticko-pragmatický kontext, v němž se vyskytují. Setkává-li se dítě v běžném životě s vodovodem, pravděpodobněji v tomto kontextu slýchá slovo voda než vést/vodit[16]; setkává-li se s kolotočem, slýchá slovo točit se; setkává-li se však se strojvedoucím, slýchá spíše slova řídit/vlak/mašinka, což jsou slova používaná dětmi v odpovědích na strojvedoucího nejvíce.
Snad by daný problém bylo možné vyřešit pečlivějším výběrem slov, která mají zcela zřetelnou slovotvornou motivaci. Kompozitum strojvedoucí již v tomto ohledu zdá se vybočuje, neboť při vysvětlení jeho motivace (které s velkou pravděpodobností postupuje od představy referentu a lexikálního významu slova ke snaze „napasovat“ na ně morfologicky identifikované kořeny) je třeba provést právě sémantické inference mezi vlak-stroj a řídit-vést. Omezíme-li se však ještě důsledněji na kompozita se zcela transparentní motivací, ponese to s sebou prohloubení problému, jak rozlišit mezi pouhým popisem referentu slova a vysvětlením jeho slovotvorné motivace, který úzce souvisí se zmiňovaným syntakticko-pragmatickým kontextem, v němž se kompozita vyskytují. Pro mnohá kompozitní pojmenování popis referentu se slovotvornou motivací splývá (kolotoč, dalekohled). Berková (1958) se ve své studii také, byť spíše okrajově, věnovala dětské analýze utvářenosti (anglických) kompozit:
„Dětská vysvětlení se dají zhruba rozdělit do čtyř kategorií. První z nich je identita: ‘A blackboard is called a blackboard because it is a blackboard.’ Druhou je tvrzení o dominantním [162]rysu nebo funkci daného objektu: ‘A blackboard is called a blackboard because you write on it.’ V případě třetího typu vysvětlení je dominantní rys objektu totožný s částí jeho pojmenování: ‘A blackboard is called a blackboard because it is black.’; ‘A merry-go-round is called a merry-go-round because it goes round and round.’ Poslední je etymologický typ vysvětlení podávaný obvykle dospělými – bere v potaz obě složky pojmenování a není nutně spojen s některým dominantním rysem nebo funkcí pojmenovávané skutečnosti: ‘Thanksgiving is called Thanksgiving because the pilgrims gave thanks.’“ (Berko, 1958, s. 168n.)
Tento problém nás staví před zásadní otázku, jak validní je použitá metoda rozhovoru pro náš záměr rozpoznat, zda dítě identifikuje (morfologické) konstituenty kompozit. Součástí tohoto problému je rovněž spolehlivost skórování dětských odpovědí, v jehož metodě jsme se v naší studii odchýlili od postupů Krottové a Nicoladisové[17]. Jde o komplexní otázku, které zde není možné věnovat dostatek prostoru; podrobnějšímu rozboru metodické validity (včetně skórování) se proto budeme věnovat v samostatné studii.
5 Závěr
Naše studie se zabývala dětskou schopností identifikovat konstituenty českých kompozit. Zjišťovala, zda se u této schopnosti projeví efekt velikosti kompozitní rodiny, tedy zda budou děti snáze identifikovat konstituenty, které znají jako součást více různých kompozit. Tento efekt se v našem vzorku projevil jen velmi omezeně, jako dominantní faktor předvídající úspěšnost dítěte jsme identifikovali pouze znalost motivujícího slova daného konstituentu.
V této studii jsme se pokusili navázat na studii Krottové a Nicoladisové (2005) a ověřit platnost jejich výsledků v upravených podmínkách také pro češtinu a české děti. Narazili jsme však na mnoho otevřených otázek, které si žádají více pozornosti a další studium jak problému efektu velikosti rodiny v češtině, tak především problému validity dané metody pro stanovené výzkumné otázky.
LITERATURA
AIKHENVALD, A. Y. (2007): Typological Distinctions in Word-formation. In: T. Shopen (ed.), Language Typology and Syntactic Description: Volume 3, Grammatical Categories and the Lexicon. 2. vyd. Cambridge: Cambridge University Press.
BAUER, L. (1983): English Word-Formation. Cambridge: Cambridge University Press.
BERKO, J. (1958): The Child’s Learning of English Morphology. Word, 14, s. 150–177.
BLOOM, P. (2000): How Children Learn the Meanings of Words. Cambridge, MA: MIT Press.
BOZDĚCHOVÁ, I. (1995): Tvoření slov skládáním. Praha: Institut sociálních vztahů – nakladatelství.
[163]CLARK, E. V. (1995): Lexicon in Acquisition. Cambridge: Cambridge University Press.
ČERMÁK, F. – KŘEN, M. (eds.) (2004): Frekvenční slovník češtiny. Praha: Nakladatelství Lidové noviny.
de JONG, N. H. et al. (2002): The Processing and Representation of Dutch and English Compounds: Peripheral Morphological and Central Orthographic Effects. Brain and Language, 81, s. 555–567.
DOKULIL, M. (1967): Tvoření slov v češtině I. Teorie odvozování slov. Praha: Nakl. Československé akademie věd.
DRESSLER, W. U. (2007): Compound Types. In: G. Libben – G. Jarema (eds.), The Representation and Processing of Compound Words. New York: Oxford University Press.
HAMAN, E. (2003): Early Productivity in Derivation. A Case Study of Diminutives in the Acquisition of Polish. Psychology of Language and Communication, 7, s. 37–56.
KADLECOVÁ, A. (2013): Několik aspektů dětského porozumění motivovanosti českých kompozit. Diplomová práce. Olomouc: Filozofická fakulta Univerzity Palackého v Olomouci.
KROTT, A. – NICOLADIS, E. (2005): Large Constituent Families Help Children Parse Compounds. Journal of Child Language, 32, s. 139–158.
MATTHEWS, P. H. (1991): Morphology. 2. vyd. Cambridge: Cambridge University Press.
NICOLADIS, E. – KROTT, A. (2007): Word Family Size and French-Speaking Children’s Segmentation of Existing Compounds. Language Learning, 52, s. 201–228.
PAČESOVÁ, J. (1979): Řeč v raném dětství. Brno: Univerzita J. E. Purkyně.
ŠTICHAUER, P. (2013): Je možná nová klasifikace českých kompozit? Časopis pro moderní filologii, 95, s. 113–128.
VUŽŇÁKOVÁ, K. (2009): Slovotvorné kategórie a postupy v Malom slovotvornom slovníku slovenčiny na pozadí detskej reči. In: R. Šink (ed.), Čeština – jazyk slovanský 3. Sborník příspěvků z konference s mezinárodní účastí. Ostrava: Pedagogická fakulta Ostravské univerzity v Ostravě, s. 165–192.
[*] Tento výzkum byl podpořen projekty Lingvistická a lexikostatistická analýza ve spolupráci lingvistiky, matematiky, biologie a psychologie (CZ.1.07/2.3.00/20.0161) a Budování výzkumně-vzdělávacího týmu v oblasti modelování přírodních jevů (CZ.1.07/2.3.00/20.0170), spolufinancovanými Evropským sociálním fondem a státním rozpočtem České republiky, a vnitřním projektem PřF UP (IGA Matematické modely, 2013_013).
[1] Srov. kritický výklad u Blooma (2000, kap. 2). O vlivu slovotvorby se však Bloom nezmiňuje.
[2] Dosavadní výzkum viz např. Vužňáková (2009), Pačesová (1979), Haman (2003).
[3] Srov. např. klasifikační návrh Štichauerův (2013).
[4] Odhlédneme-li pro tuto chvíli od sémantické specializace, kterou není vždy snadné analyzovat.
[5] Přehled o povaze anglických compounds viz např. Bauer (1983), Matthews (1991), Dressler (2007). O rozdílech ve stavbě ‚kompozit‘ napříč jazyky viz Aikhenvald (2007).
[6] Pro 17 z 27 dospělých dotazovaných v našem výzkumu je např. slovo dobrovolník i při vědomě zacíleném rozboru zřejmě vnímáno jako neanalyzovatelné (říká se mu dobrovolník, „protože něco dělá dobrovolně“). Viz také Berko (1958, s. 169n.).
[7] Překlad z angličtiny (i ve všech ostatních případech): A. K.
[8] Efekt se neprojevil u anglických kompozit psaných dohromady, ani u holandských kompozit (viz de Jong et al., 2002).
[9] Pro podrobné výsledky dotazníků pro dospělé viz Kadlecová (2013, s. 41n.).
[10] Průměrná IVR menší než jedna byla výsledkem faktu, že děti (podle RD) leckdy neznaly ani jedno kompozitum s daným konstituentem.
[11] Výchozí je pro nás terminologie Miloše Dokulila (Dokulil, 1967) a Ivany Bozděchové (Bozděchová, 1995).
[12] Údaje v závorce mají formát (identifikační kód subjektu; pohlaví; věk, tj. R;M).
[13] První dva autoři studie hodnotili odpovědi společně, takže jejich hodnocení bylo poté při výpočtu mezihodnotitelské shody pojímáno jako jediné hodnocení; zvlášť hodnotil odpovědi třetí autor studie.
[14] Spearmanův korelační koeficient pro vztah mezi korpusovou VR a průměrným skóre (n=40, rs=0,13, p=0,4) ani pro vztah mezi průměrnou IVR a průměrným skóre (n=40, rs=0,23, p=0,16) není podle testů statisticky významně odlišný od nuly.
[15] K přechodným typům viz Dokulil (1967, s. 22), např. pantáta či lidumil.
[16] Konstituent -vod patřil v tomto výzkumu k těm, které děti zmiňovaly ve svých odpovědích nejméně.
[17] Na rozdíl od nás autorky více využívaly jednobodové hodnocení, a to pro odpovědi obsahující slova pouze sémanticky příbuzná kompozitním konstituentům (viz Krott – Nicoladis, 2005, s. 146).
Anna Kadlecová
Katedra obecné lingvistiky FF UP v Olomouci, Ústav obecné lingvistiky FF UK v Praze
Myslíkova 27, 110 00 Praha 1
anicka.kadlecova@gmail.com
Marek Nagy
Katedra obecné lingvistiky FF UP v Olomouci
Kateřinská 17, 771 80 Olomouc
marek.nagy@upol.cz
Barbara Mertins
Institut für Deutsch als Fremdsprachenphilologie, Neuphilologische Fakultät, Ruprecht-Karls-Universität Heidelberg
Plöck 55, 691 15 Heidelberg, Germany
mertins@idf.uni-heidelberg.de
Sandra Donevska
Katedra geoinformatiky a Katedra matematické analýzy a aplikací matematiky PřF UP v Olomouci
17. listopadu 12, 771 46 Olomouc
sandra.donevska@upol.cz
Naše řeč, ročník 97 (2014), číslo 3, s. 146-163
Předchozí Barbora Kukrechtová: Rodinná korespondence Karla Havlíčka v českých překladech
Následující Marie Krčmová: Znovu o mediálním dialogu
© 2011 – HTML 4.01 – CSS 2.1