
Střídání kódů či míšení jazykových prostředků? (K popisu dialogu v české beletrii)
Neil Bermel
[Articles]
-
[1]1. Úvod
Tato stať analyzuje jeden typ textu – dialog v beletrii – z hlediska dvou rozšířených jazykových útvarů na českém území. Česká jazyková situace už dávno poutá pozornost lingvistů tím, že disponuje psanou variantou (spisovnou češtinou, dále SČ) vedle několika dost odlišných mluvených variant, z nichž nejrozšířenější je čeština obecná (dále OČ). V češtině se údajně vybírá mezi variantami podle způsobu vyjádření (psanosti-mluvenosti), ale i podle dalších funkčních kritérií (viz níže 2).
Beletristický dialog je zvlášť zajímavý tím, že svou pouhou existencí vytváří přechodný prostor mezi SČ a OČ. Vzhledem ke způsobu vyjádření patří literární dialog do sféry SČ, jelikož je psaným, veřejným textem. Avšak vzhledem k charakteru textu je literární dialog spíše textem neformálním, důvěrným, soukromým, a navíc je reprezentací textu mluveného. Výsledkem tohoto rozporu mezi formálním ztvárněním a textovým charakterem je skutečnost, že by mohlo docházet k častému kolísání mezi používanými tvary. Zatím však není ve vědecké literatuře dostatečně dokázáno, za jakých okolností a kterými jazykovými prostředky by se toto kolísání realizovalo.[2] Proto vznikla myšlenka zkoumat tento druh psaného jazyka pomocí nevelkého označkovaného korpusu literárního dialogu.
Nejdříve vyložíme definice termínů používaných v bohemistice a obecné lingvistice. Analýzou příkladů z běžného hovoru a z literatury se pak pokusíme zjistit, nakolik lze užívání jazykových prostředků zařadit do daných lingvistických přihrádek. Dále se budeme zabývat znaky nespisovnosti v literárním dialogu a pokusíme se z toho vyvodit závěry. Na základě těchto údajů položíme otázku, nakolik musíme změnit model „dvou češtin“, s nímž jsme začali svůj výklad.
[17]2. Základní popis jazykové situace v Čechách
Pro nepříliš kontroverzní začátek předpokládáme, že v běžném úzu obyvatel Čech existují dva základní útvary češtiny:
SČ je společným psaným jazykem celého českého národa, který se užívá skoro ve všech psaných kontextech a ve formálních mluvených situacích. Pojetí „formální mluvené situace“ se ale postupně úží, a proto SČ v některých komunikačních situacích ustupuje, jako je tomu např. v různých televizních pořadech, ve filmech apod.[3]
OČ je původně místním nářečím Prahy a středních Čech. V širším pojetí je to „interdialekt“, tj. nářečí, které se uplatňuje (bez některých úzce středočeských prvků) i mimo své původní území a do kterého pronikají regionální varianty.[4] Podle některých lingvistů[5] se už téměř nedá mluvit o různých nářečích v Čechách a zčásti ani na západní Moravě: jde spíše o regionální varianty obecné češtiny s poměrně nesoustavnými rozdíly. Obecnou češtinou mluví podle těchto badatelů 50 až 60 procent obyvatelstva ČR. Na Moravě a ve Slezsku je její užívání mnohem omezenější, na svém území je však OČ prostředkem běžných hovorů takřka v převážné většině neformálních situací. Jak už bylo zmíněno, pojetí „neformální situace“ se poněkud rozšiřuje, a proto proniká i do tradičních sfér SČ (televize, rozhlas, film, do určité míry i beletrie).
Většina jazykových prostředků v češtině však není diferencovaná, tj. patří jak ke spisovným, tak k obecněčeským prostředkům vyjadřování. Můžeme tedy položit otázku: jak často se takové „diferenční prostředky“ vyskytují? Nemáme k dispozici údaje, které by svědčily o celkové situaci v češtině, s pomocí našeho korpusu jsme ale odhadli, že v literárním dialogu se takový diferenční prostředek vyskytuje přibližně v jednom slově z devíti až v jednom slově ze šesti v závislosti na typu textu[6].
Tyto prostředky slouží k rozlišování kódů jednotlivých textů. Popis založený na takovém hledisku ovšem předpokládá, že v jistém okamžiku se užívají prostředky buď jednoho, nebo druhého kódu, tj. dá se říci, že se text vždy nachází plně v jednom ze dvou (nebo případně více) kódů. Vyskytnou-li se situace, ve kterých se setkáváme v těsném sousedství s prostředky obou kódů, pak se předpokládá, že platí obecnělingvistické principy o tzv. „střídání kódů“. Zde záměrně užíváme nejneutrálnějšího termínu, který odpovídá anglickému „code alternation“ a v současné době se těší mezi badateli čím dál větší oblibě: nejběžnější anglický termín je [18]však stále „code switching“, tj. doslovně „přepínání kódů“.[7] V klasickém modelu se kódy skutečně přepínají, tj. jde o okamžitý přechod z jednoho kódu do druhého, a díky tomu lze zařadit každý jazykový okamžik do jedné z daných „přihrádek“, tj. stanovit, že jde o jednu či druhou jazykovou varietu.
Většina studií o střídání kódů je založena na výzkumech dvojjazyčných společností, v nichž se mluví např. anglicky i španělsky. Analýza situace, v níž se v kontaktu nacházejí úplně rozdílné jazyky, má oproti situaci, již rozebíráme, jisté výhody. Především v ní jde o poměrně precizní vyhranění kódů: i když z lexikálního nebo morfologického hlediska není snadné nebo možné rozhodnout, který kód mluvčí užívá, lze to často určit podle přízvuku nebo výslovnosti. V češtině zřejmě nejde o tak jasnou situaci, podle které by skoro každé slovo patřilo buď do jednoho, nebo do druhého kódu: pro většinu fonémů, a tedy pro mnoho slov, neexistují závažné rozdíly mezi výslovností v OČ a SČ.[8]
(1) Jak se kódy mají „střídat“ nebo „přepínat“:
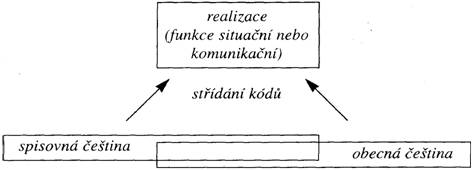
Graf číslo 1 zobrazuje, jak se má ze dvou základních variet realizovat český text střídáním kódů. Pro každý text existují dva „zdroje“, původní kódy SČ a OČ, které se do určité míry vzájemně kříží. Impulzy ke střídání může způsobit buď celková jazyková situace (tj. povaha textu, jaké jsou okolnosti vzniku textu atd.), nebo tzv. komunikační faktory.[9] Situační funkce se málokdy mění během jednoho úseku textu, na rozdíl od komunikačních funkcí, které se mění dost často.[10] Z často cito[19]vaných impulzů můžeme jmenovat např. podle P. Auera, J. Bloma a J. Gumperze[11] tyto: přechod mezi přímou a nepřímou řečí (direct vs. indirect speech); změna účastníků hovoru (change of participant constellation); odchylky od hlavní linie hovoru (use of parenthetical comments); opakování (reiteration); změna typu hovoru (change in activity type); posun v předmětu hovoru (topic shift); slovní hříčky (puns); záměrné aktualizace jazykových prostředků (language play); vliv aktuálního členění (factors related to topicalization).
Nyní se budeme zabývat otázkou, zda tato pravidla přepínání opravdu platí pro češtinu (platí i pro češtinu?), a to jak v běžné mluvě, tak v literárním dialogu.
3. Výskyt SČ a OČ v mluvě
Práce americké lingvistky Louise Hammerové ukazuje, že mezi systémy spisovnosti a nespisovnosti nejsou jasné hranice, ale jde tu spíše o míšení tvarů s různými stupni přijatelnosti. Hammerová nahrála několik konverzací mezi svými českými známými a provedla analýzu jazykové variantnosti, především výskytu fonologických prostředků OČ a SČ. Většina jejího materiálu není zveřejněna, ale v krátkých úryvcích publikovaných u P. Sgalla a J. Hronka[12] se tvary OČ a SČ spojují v jedné větě, ba dokonce i v jednom slově: vona si pamatuje na konec minulého století; do opatroven pro vopuštený děti; pro opuštěný děti atd. Podle konvenčních pravidel střídání kódů bychom očekávali, že by tato střídání měla být motivována buď situačně, nebo komunikačně.
Situační motivace zde nejsou rozhodující. Jde o soukromý rozhovor, mluví se však o literatuře a jejím vlivu na veřejnost, což je do určité míry téma ne zcela soukromé. Mluvčí jistě cítila vliv obou faktorů a to mohlo vést ke kolísání mezi kódy. Jasné důkazy situačních změn, které by způsobily střídání kódů, ale nenalezneme.
Komunikační impulzy také mnoho nepomohou. Občas je možné zdůvodnit přepnutí na základě výše uvedených podnětů (např. opakování výrazu), ale zdaleka ne vždy. Ať už mluvíme o přepínání nebo střídání kódů, v těchto ukázkách [20]se střídají občas nahodile. Nejlepším dokladem toho je slovo opuštěný (děti), jehož začátek vykazuje rys SČ a konec rys OČ. Z toho můžeme usoudit, že s tradičním modelem střídání kódů nevystačíme.
4. Výskyt SČ a OČ v literárním dialogu
Dialog v beletrii má problematickou podstatu, protože existuje jasný rozpor mezi dějovou situací a situací textovou. Rozhovor, který se údajně zachycuje na papíře, může být důvěrný a soukromý, avšak zároveň se odehrává vlastně na veřejné scéně, tj. v románě, což je psaný text, dostupný všem. Dějová situace je argumentem pro nespisovnost, textová situace argumentuje spíše pro spisovnost, a proto tu spisovatel má na vybranou: užívá-li důsledně tvary OČ, ignoruje spisovnost textu, a užívá-li důsledně tvary SČ, ignoruje zvyklosti denního styku v češtině a vytváří text tak, jak by ho nikdo nepronesl. Tento rozpor nutně vede spisovatele ke kompromisu, jehož výsledky najdeme skoro v každém úryvku textu (následující příklad je z hovoru, ve kterém mladý pár mluví o svých plánech natočit film).
(4) Jak se užívají OČ a SČ v literárním dialogu?
„To bychom byli jediní Češi v celým štábu?“ uvědomila si.
„Ještě střihač. Stříhal by Jirka. Ten je nejlepší na světě. Musím tě s ním seznámit, možná se do něho zamiluješ.“
„Jak vypadá?“
„Jirka? Je asi o deset cenťáků větší než já…“
„To snad není možný?“
„Je, a má sílu jako bagr. Loni tady byl pár dní se mnou. Potřeboval jsem suchý stromy na topení a on je kácel tím způsobem, že je bafl za kmen a prostě je vytrhl ze země.“
„Kde dělá?“
„V televizi…“[13]
Prostředky OČ jsou podtrženy jednoduše; prostředky SČ jsou podtrženy dvojitě.
I zde pozorujeme nemotivované kolísání mezi OČ a SČ (jediní Češi v celým štábu) a střídání kódů mezi předložkou a substantivem (o deset cenťáků). Kvantita a proporce tvarů budou v literárním dialogu samozřejmě jiné než v běžné řeči, ale i zde zůstane zřejmá zásadní neadekvátnost kódového popisu.
5. Měření adekvátnosti prostředků
Třebaže někteří z bohemistů, jak českých, tak zahraničních, jsou toho názoru, že kódový popis může s jistými adaptacemi platit i pro češtinu (viz práci P. Sgalla [21]a jeho spolupracovníků, d. cit. v pozn. 4), hlavní směr výzkumu mezi bohemisty vedl jinam. Předmětem jejich bádání byla rozdílná použitelnost a přijatelnost těchto diferenčních prostředků češtiny.
Zásadní otázka, která tedy stála před badateli, zněla: jak se měří „přijatelnost“? Přijatelnost je těsně spjata s pojetím normy, takže šlo vlastně o měření jazykové normy. V závislosti na tom, jak se chápala jazyková norma, se vytvářely dva směry ve výzkumu.
První postup vycházel z koncepce, že norma je věcí estetickou, vyjadřovanou jazykovými názory a preferencemi každého přemýšlejícího rodilého mluvčího, a proto se normy dají zjistit pomocí pohovorů s rodilými mluvčími. V těchto pohovorech badatelé víceméně otevřeně žádali vybrané mluvčí o hodnocení přijatelnosti tvarů a výrazů v určitých kontextech. Dvě nejznámější studie tohoto typu provedli američtí badatelé H. Kučera a Ch. Townsend[14].
Druhý postup vyplýval spíše z přesvědčení, že jazyková norma existuje jen a jen v úzu, a proto je analýza normy mimo dosah obyčejného mluvčího. Posudky mluvčích často selhávají, neboť neodpovídají úzu, a proto je potřebné zjistit normu jiným, spolehlivějším způsobem, tj. pomocí analýzy už existujících textů. Z těchto studií můžeme jmenovat práce K. Kravčišinové a B. Bednářové, L. Hammerové, D. Davidové a jejího kolektivu a K. Gammelgardové[15].
V obou postupech je zřejmě skryt předpoklad, že slova „spisovný“ a „obecný“ jsou málo sdělná, alespoň co se týče hodnocení a frekvence výskytu jednotlivých prostředků v textech. Jinak řečeno, označkování prostředků slovem „obecná čeština“ neříká nic o tom, že se tyto prostředky projevují ve všech mluvených textech stejně často a se stejnou konotací. Všechny studie uvádějí, že některé prostředky jsou přijatelné až v 90 procentech kontextů, jiné jen v 10 procentech, zatímco ostatní prostředky se umísťují někde na škále mezi oběma dvěma póly.
Dalším zajímavým výsledkem těchto studií bylo, že se navzájem neshodovaly v tom, které prostředky jsou přijatelnější. Zdálo se, že lidé hodnotí své projevy jinak, než je skutečně formulují: dokáží dokonce odsuzovat a popírat existenci tvarů a kombinací slov, které právě použili v řeči. Podle J. Krause[16] mohou existovat dokonce dvě jazykové normy: norma úzu (norm of usage) a norma hodnocení (norm of evaluation). Tato formulace vyplývá z dřívější formula[22]ce ve stati J. Krause a kol.,[17] v níž se mluví o stanoviscích k jazyku objektivních (založených na sledovaném a analyzovaném úzu) a subjektivních (založených na osobním citu pro jazyk). Otázka zní: Platí i pro literární dialog jedna z hierarchií stanovených pro mluvenou češtinu, a pokud ano, která z nich to je?
6. Složení korpusu
Současný projekt se zakládá na označkovaném korpusu o rozsahu 30 000 slov z tří současných českých románů, a to Čekání na tmu, čekání na světlo od Ivana Klímy (Praha 1993), Sněžím od Pavla Kohouta (Praha 1993) a Oční kapky od Lenky Procházkové (Brno 1993). Ve všech třech románech se děj odehrává v Praze a jde v nich o důležité sociální a osobní otázky normalizačního a polistopadového života. Při vybírání zdrojů jsme se řídili hlediskem společného tématu a pozadí: Protože nám jde o lingvistickou analýzu existujících textů a ne o doporučení budoucím spisovatelům, jak se má psát, nepovažujeme za relevantní rozdílné posudky literárních kritiků o hodnotě daných děl.
Na rozdíl od práce K. Gammelgaardové (d. cit. v pozn. 2), která se zakládá na tzv. „undergroundové“ literatuře, obsahující mnohé nespisovné prvky jak ve vyprávění, tak v dialogu, vyprávění ve všech třech našich textech patří jednoznačně do SČ. To poněkud zjednodušuje naši práci, protože si můžeme být jisti, že najdeme-li nespisovné prostředky v dialogu, nejde o celkovou stylizaci textu, nýbrž o snahu zachytit reálnou řeč a charakterizovat jednotlivé postavy a jejich interakci v rámci spisovného textu.
V korpusu byly označkovány prostředky fonologické, morfologické, syntaktické a lexikální, které se obecně považují za rysy OČ nebo SČ. Tento článek se zabývá jen hláskoslovnou a tvaroslovnou stránkou.[18]
7. Hláskosloví
V sloupcích tabulky 5 jsou uvedeny čtyři nejznámější fonologické korespondence mezi SČ a OČ. Značka Ml odkazuje k frekvenci prostředků OČ v mluvené řeči podle K. Kravčišinové a H. Bednářové (d. cit. v pozn. 15), ostatní značky odkazují k výše uvedeným autorům. Pro první dva prostředky rozlišujeme tři pozice ve slově, a to tradičně podle Kučery a dalších: poloha kmenová (-é-, -í-), koncová (-é, -í), a poloha v koncovce, ale ne koncová (-éC, -íC).[19] Podobně se třetí (a někdy i čtvr[23]tý) prostředek dělí na pozice na počátku slova (#vo, #ou) a na počátku neiniciálního kmene (-vo, -ou).
(5) Hláskosloví v třech textech a v mluvě
| OČ = SČ | /í/ = /é/ | /ej/ = /í/ | /vo/ = /o/ | /ou/ = /ú/ |
| 90–99 % | Ml 93 -íC | Ml 95 -ej |
|
|
| 80–89 % | Ml 87 -í | Ml 81 vo |
|
|
| 70–79 % | Pr 73.9 -í | Ml 71 -ejC |
|
|
| 60–69 % |
| Pr 68.4 -ejC |
|
|
| 50–59 % | Pr 58.3 -í- |
|
|
|
| 40–49 % | Ml 45 -í- | Pr 45.8 -ej- |
|
|
| 30–39 % | Ko 38.5 -í- |
|
|
|
| 20–29 % |
| Ko 26.3 -ej- |
|
|
| 10–19 % | Kl 11.8 -í- |
| Ko 16.7 -v |
|
| 1–9 % | Kl 6.1 -í | Ko 6.3 -ejC |
| Ml 6 ou |
| 0 % |
| Kl 0.0 -ej(C) | Pr 0.0 vo | Ko 0.0 ou |
Polohy ve slově:
-í, -ej = koncová poloha
-íC, -ejC = jinde v koncovce
-í-, -ej- = kmenová poloha
#vo = počáteční poloha ve slově
= počáteční poloha ve kmenu
Jiné zkratky:
Ko = Kohout
Kl = Klíma
Pr = Procházková
Ml = Mluva (veřejná i soukromá) podle Kravčišinové a Bednářové (d. cit. v pozn. 15)
Tyto údaje o hláskosloví jsou z některých hledisek pozoruhodné.
Za prvé: v mluvě někteří badatelé – nejen K. Kravčišinová a B. Bednářová, ale i H. Kučera, Ch. Townsend a L. Hammerová – zaznamenali jistou stupňovitost v užívání nespisovných tvarů. Ačkoli absolutní frekvence tvarů se liší v závislosti na autorovi, tento žebříček stupňů se tu celkově potvrzuje: nejužívanější je v kaž[24]dém textu OČ foném /ý-í/ místo SČ /é/, dále /ej/ místo /ý-í/, /vo/ místo /o/ a konečně /ou/ místo /ú/.
Za druhé: OČ fonémy se vyskytují v řeči o něco častěji než v literárním dialogu. Zde narazíme na otázku, čím je to způsobeno. Vždyť údaje o mluvené češtině zahrnovaly i veřejné projevy, a proto bychom mohli čekat, že čistě soukromé hovory v psaných textech budou mluveným tvarům přístupnější – ale není tomu tak. Psanost a nepsanost má zřejmě větší vliv na výběr tvarů než charakter komunikační situace.
Za třetí: u prvních dvou korespondencí uvedených výše (OČ /ý-í/ místo SČ /é/, a OČ /ej/ místo SČ /ý-í/) platí větší výskyt mluvených tvarů v řeči oproti literárnímu dialogu hlavně pro polohy v koncovkách. Tím už jsme se zbavili valné většiny výskytů, protože koncovkové polohy jsou mnohem běžnější než polohy uvnitř kmene. U kmenových poloh toto pravidlo ale neplatí. Mluvené tvary se vyskytují alespoň v jednom literárním textu častěji než v mluvě. Domníváme se, že kmenová poloha je méně stabilní než ostatní polohy, tj. čekáme tu větší rozdíly jak mezi jednotlivými slovy, tak mezi jednotlivými autory. To snad nikoho nepřekvapí, protože výběr v kmenové poloze záleží hlavně na tom, jak každý vnímá potenciál jednotlivých kmenů. Někdo např. napíše nebo řekne bejt a ne být, ale váhá u mlejn – mlýn – nebo naopak.[20]
Za čtvrté: v případě opozice vo-o jde o značný rozdíl mezi texty literárními a texty opravdu mluvenými. Připomeňme si práci Ch. Townsenda (d. cit. v pozn. 14), který píše o variabilitě iniciálního /v/ v pražské mluvě. Podle jeho konzultantů může být iniciální /v/ vysloveno někdy velice silně, ale jindy tak jemně, že si jej ani moc nevšimneme. Obyčejná česká písmena a fonty nedisponují takovou škálou možností. Autorovi beletristického textu zbudou dvě možnosti: napsat v-, anebo jej nenapsat. Tento výběr mezi možnostmi je tvůrčí čin: je to rozhodování mezi dvěma ne zcela adekvátními způsoby vyjadřování. V tomto kontextu je vhodné zmínit se o další souvislosti, tentokrát s prací amerického slavisty Kučery. V 50. a 60. letech čeští badatelé stroze kritizovali Kučeru za to, že ve svém výzkumu ne[25]chal informátory přímo komentovat a hodnotit přijatelnost lingvistických jevů (viz K. Kravčišinová a H. Bednářová, d. cit. v pozn. 15, F. Daneš, d. cit. v pozn. 3). Říkalo se, že by místo toho měl tyto jevy zaznamenávat v běžném úzu. Vzhledem k tvrzení J. Krause (d. cit. v pozn. 16, viz výše), že v češtině, a možná v každém jazyce, může existovat vedle normy úzu i norma hodnocení, vzniká další otázka, nakolik se literární dialog podobá dialogu skutečnému, tj. normě úzu, a nakolik se podobá estetickým posudkům, resp. normě hodnocení. Soudě jenom podle nízkého výskytu vo- bychom zařadili literární dialog do sféry normy hodnocení. Jeho frekvence v literatuře odpovídá spíše nízkým posudkům Kučerových informantů než jeho dost častému výskytu v řeči.
8. Tvarosloví
Výskyt OČ morfologických prostředků v našich textech je zachycen v tabulce 6. Přehled prostředků je uveden v tabulce 7.
(6) Tvarosloví v třech textech a v mluvě
| Prostředek | Procházková | Kohout | Klíma | Průměr | V řeči |
| #můžu 8 | 100.0 | 58.3 | 100.0 | (86.1) | 96 |
| #říct 14 | 100.0 | 100.0 | 100.0 | (100.0) | 90 |
| lidi 6 | 100.0* | 100.0* | 77.3 | (92.4) | – |
| #pracuju 12 | 100.0 | 92.9 | 100.0 | (97.5) | 89 |
| nes 9 | 33.3 | 39.0 | 20.7 | (31.0) | 79 |
| bysme 2 | 0.0 | 0.0 | 0.0 | (0.0) | 75 |
| nový auta 3 | 100.0* | 66.7* | 14.3 | (60.3) | 69 |
| #můžou 7 | 100.0* | 100.0* | 100.0* | (100.0) | 57 |
| pánama 10 | 61.1 | 44.0 | 32.0 | (45.7) | 53 |
| dělaj, sázej 5 | 60.0 | 5.3 | 0.0 | (21.8) | 43 |
| dobrý hráči 4 | 33.3* | 60.0 | 0.0 | (31.1) | 39 |
| #pracujou 11 | 40.0* | 75.0* | 28.0 | (61.0) | 34 |
| vedem 17 | 78.9 | 88.9 | 0.0 | (55.9) | 29 |
| prosej(í) 13 | 71.4* | 26.7 | 0.0 | (32.7) | 28 |
| #sází 16 | 0.0 | 0.0 | 0.0 | (0.0) | 13 |
| s dobrym 15 | 0.0 | 10.0 | 0.0* | (3.3) | – |
| bysem 1 | 0.0 | 3.0 | 0.0 | (1.0) | – |
| průměr (17) | (57.5) | (51.2) | (33.7) | ((47.5)) | – |
| průměr (14) | (62.7) | (54.1) | (35.4) | ((50.7)) | (56.7) |
# = užívá se někdy i v SČ vedle „spisovnějšího“ tvaru
* = počet příkladů v korpusu pod 10
Průměry v závorkách jsou zde uvedeny jen pro snazší orientaci v tabulce, nepřipisujeme jim žádný zásadní význam.
[26](7) Klíč k morfologickým prostředkům (OČ – SČ)
| 1. bysem – bych | 10. pánama/kostma – pány/kostmi |
| 2. bysme – bychom | 11. pracujou (#) – pracují |
| 3. nový auta – nová auta | 12. pracuju (#) – pracuji |
| 4. dobrý hráči – dobří hráči | 13. prosej(í) – prosí |
| 5. dělaj/sázej – dělají/sázejí | 14. říct (#) – říci |
| 6. lidi (#) – lidé[21] | 15. s/o dobrym – s dobrým, o dobrém |
| 7. můžou (#) – mohou | 16. sází (#) – sázejí |
| 8. můžu (#) – mohu | 17. vedem – vedeme |
| 9. nes – nesl |
|
Sledovali jsme kolem 30 morfologických prostředků, z nich jsme získali dostatečné informace o 17, a ty jsou zde zachyceny v levém sloupci tabulky 6. V dalších třech sloupcích této tabulky najdeme výskyt OČ varianty v každém textu, uvedený v procentech. V pravém sloupci jsou údaje K. Kravčišinové a H. Bednářové, d. cit. v pozn. 15. Procenta tu opět vyjadřují výskyt nestandardních variant.
Uvedené průměry mají umožnit jen snadnou orientaci ve výskytech prostředků v textech. Vzhledem k malému rozsahu korpusu svědčí tato čísla jenom o aglomeraci prostředků ze tří textů, ale neposkytují úplný přehled o literárním dialogu. V druhém sloupci zprava je uveden průměrný výskyt každého prostředku, dole pak průměrný výskyt všech prostředků v každém textu: nejdříve všech 17 prostředků sledovaných námi, dále jen 14 prostředků, které také sledovaly K. Kravčišinová a H. Bednářová. Vpravo a dole ve dvojitých závorkách jsou uvedeny celkové průměry – ty však jsou užitečné jen pro orientační srovnání.
Z těchto údajů lze vyvodit několik závěrů. (1) Celkem vzato se zdá, že průměrný výskyt ne plně spisovných tvarů není nepodobný tomu, co bylo nalezeno v řeči. Vedle značně nižšího výskytu hláskoslovných prostředků je to obzvlášť pozoruhodné a nabízí se závěr, že morfologické prostředky OČ jsou přijatelnější v literárním dialogu než prostředky hláskoslovné. (2) Jsou ovšem rozdíly mezi mluvenými a psanými texty, ale neplatí, že se každý OČ prostředek vyskytuje častěji v hovoru než v literatuře – občas tomu bývá naopak. Zejména bychom chtěli upozornit na velice nízký výskyt mluvených variant typu nes a bysme, které se hojně užívají v řeči, ale málo – téměř nikdy – ve sledovaných literárních dialozích. Z druhé strany si všimněme značně vyššího výskytu ne plně spisovných variant typu vedem, pracujou, můžou v literárním dialogu.[22] (3) Na první pohled se zdá, že jde o posílení po[27]zice zespisovnělých tvarů v literatuře, to však popírá absence tvarů typu „sází“. Tady zase jde zřejmě o jakousi estetickou stupnici tvarů, a nikoli o čistě oficiální stupnici přijatelnosti. (4) Pozoruhodný je také výrazně nízký výskyt nespisovných tvarů u Klímy ve srovnání s Kohoutem a Procházkovou, ačkoli tu zase pozorujeme podobný žebříček hodnot, jenom s nižší frekvencí.
9. K modelu užívání prostředků
Nyní se vrátíme k otázce, jak lze charakterizovat a pojmenovat užívání jazykových variet v psaném dialogu. Vracíme se zpět k tvrzení, že výskyt nespisovných tvarů se v češtině zdá být určován nejenom situačními rozdíly, ale zejména přijatelností nebo nepřijatelností spisovných a nespisovných variant. Abychom tuto situaci popsali, potřebujeme model složený z dvou částí. První část představuje škálu přijatelnosti jednotlivých jazykových prostředků a druhá část určuje celkový charakter textu.
V sestavování první části tohoto modelu jsme se opírali o tvrzení různých badatelů[23], že v češtině často chybí adekvátní tvar a že často dochází k situaci, ve které se ani spisovná varianta, ani varianta obecné češtiny nevnímá jako plně vyhovující a patřičná. Tento popis je ovšem „subjektivní“ (ve smyslu J. Krause a kol., d. cit. v pozn. 17), a proto jsme se tu snažili s pomocí korpusu vytvořit „objektivní“ popis. Měli jsme dostatek materiálu, abychom posoudili, kde došlo v různých textech k odlišným názorům na adekvátnost toho či onoho prostředku.
(8) Prostředky a jazykové roviny (registry) v textech
| Registr | Hláskosloví | Tvarosloví |
|
| Oficiální | SČ /é/ | 8SČ mohu | 6SČ lidé |
| Neutrální | SČ/#o/ | 5SČ dělají/sázejí | 80Č můžu |
| OČ /-í/ | 3OČ velký auta | 11OČ pracujou | |
| Příznakově | OČ /-i:-/ | 9OČ nes | 5OČ dělaj/sázej |
| Výrazně | OČ /#ou/ | 2OČ bysme | 15OČ s dobrym |
Tabulka 8 má poskytnout víceméně úplný přehled registrů, které potřebujeme pro popis beletristického dialogu, ale tím rozhodně netvrdíme, že tato škála stačí i pro jiné typy psaných textů. Pro popis např. vědeckých textů, nebo dokonce i pro popis vyprávění v beletrii, bychom pravděpodobně museli tuto „oficiální“ vrstvu dále roztřídit do dalších registrů, a je možné, že by v některých těchto textech chyběly nejnižší registry. K těmto textům (a registrům) se nemůžeme vyslovit, a proto si tu vybereme nejjednodušší dostačující řešení, tj. v tomto případě nejmenší počet registrů. Informace v tabulce 8 čerpá z údajů v tabulkách 5 a 6 následujícími způsoby:
(1) Prostředky, které souvisejí s tzv. „neutrálním“ registrem, jsou v literárním dialogu s víceméně „spisovným“ vyprávěním užívány nejčastěji. Vyskytují se totiž v zobrazení „neutrálního“ až „neoficiálního“ hovoru mezi vzdělanými postavami, které tvoří většinu dialogů v korpusu a které slouží především k postupu děje. Nenajdeme tu však jenom spisovné varianty: někdy jsou to tvary zespisovnělé až hovorové. V každém případě má neneutrální varianta frekvenci 0–20 procent.
(2) Čím vzdálenější je tento druhý registr od neutrálního, tím nižší je frekvence souvisejících prostředků v našem korpusu. Ze statistik např. vyplývá, že OČ prostředek typu velký auta je v těchto dialozích běžnější než prostředek typu prosej, a proto je první spojen s vyšší skupinou.
(3) Jestliže pro určitou dvojici prostředků chybí neutrální varianta, znamená to, že se v textech projevuje určitá konkurence mezi tvary, a to buď tak, že v každém textu najdeme dostatečně často oba tvary, nebo tak, že mezi texty vidíme dost značné rozdíly.
Jak jsme se už zmínili, většina hovorů zastoupených v našem korpusu se odehrává mezi hlavními postavami románů, které patří k průměrně vzdělaným lidem. V těchto textech jsou však i rozhovory s méně vzdělanými a vzdělanějšími vedlejšími postavami, které jsou také součástí korpusu. Frekvence prostředků následkem toho nezůstává v rozhovorech v průběhu jednoho románu vždy stejná, ale mění se v závislosti na povaze jednotlivých situací. Způsob mluvy postav v konverzacích, resp. celá konverzace alespoň částečně slouží k popisu jejich charakterů. Změna [29]ve způsobu mluvy působí na čtenáře, odlišuje vedlejší postavu od hlavních nejen tím, že tato postava mluví jinak než hlavní postavy, ale i tím, že i k ní se mluví jinak.[24]
Fakt, že se v těchto posunech jenom mění proporce tvarů, a nikoli zařazení tvarů do textu nebo vyřazení tvarů z textu, svědčí o dalším důležitém bodu: prostředky doprovázejí registry textů a pomáhají v určování registrů, ale registr charakterizuje text jako celek a ne jeden nebo druhý prostředek.
Pokles nebo vzestup frekvence různých variant nás upozorňuje, že se registr textu mění: Čím nižší je registr textu, tím více se v něm vyskytují tvary spojené s nižšími registry. Škály registrů v těchto textech bychom přibližně odhadli tak, jak je to uvedeno v tabulce 9. Klíma a Procházková mají rozlišné, ale poměrně stabilní registry, kdežto Kohout má velice širokou škálu registrů, v závislosti na postavách a situacích, většina konverzací se ale pohybuje ve středních registrech.
(9) Texty a registry
[30]10. Závěry
Tradičně jsme se dívali na češtinu jako na dva odlišné kódy, které jsou zahrnovány do jednoho jazykového systému. Současné studie češtiny, včetně naší, nás vedou k závěru, že tento tradiční popis je neadekvátní, jelikož mnohé jazykové prostředky zřejmě nenaznačují začlenění nebo nezačlenění do jedné z dvou variet, a místo toho vykazují mnohem jemnější stupně patřičnosti k těmto varietám.
Jestliže trváme na tom, že jsou v češtině dva základní kódy, pak se ovšem tyto kódy za daných okolností nepřepínají ani nestřídají, nýbrž se mísí. Tímto míšením vzniká škála registrů, která vede od češtiny obecné až k češtině spisovné. Toto vysvětlení však stále není uspokojivé, protože nebere ohled na funkčnost různých prostředků.
Z toho vyplývá, že se čeština podobá spíš jiným západoevropským jazykům než dvojjazyčné situaci. Pokud chceme češtinu vůbec popsat jako jazyk fungující v diglosní situaci, pak musíme od začátku připustit, že diglosní situace může zahrnovat množství propojených jazykových vrstev, nejen dvě. Známá česká hojnost fonologických a morfologických tvarů, kterými tyto vrstvy nebo registry rozlišujeme, je ovšem pozoruhodná (z formálně jazykového i sociolingvistického hlediska), ale tím se čeština liší od jiných jazyků spíš kvantativně než kvalitativně.
[1] Tento článek vznikl na základě přednášky v Jazykovědném sdružení, která se konala 11. května 2000 v Ústavu pro jazyk český v Praze. Většinou se čerpá z materiálů v autorově stati, kde najde čtenář podrobnější výklad těchto údajů. Autor děkuje za radu a pomoc v přípravě českého článku PhDr. Světle Čmejrkové, CSc., prof. PhDr. Jiřímu Krausovi, DrSc., PhDr. Ludmile Uhlířové, CSc. (ÚJČ AV ČR), a PhDr. Ivaně Bozděchové, CSc. (FF UK). Za četné připomínky při přípravě anglické verze je nadále vděčen prof. PhDr. Petru Sgallovi, CSc. (MFF UK), prof. Karen Gammelgaardové (Univerzita v Oslu, Norsko) a doc. Nigelu Gotterimu (Univerzita v Sheffieldu, Anglie).
[2] K. Gammelgaardová (Spoken Czech in Literature, Oslo 1997) se zabývá problematikou jazykových útvarů v undergroundové literatuře 50. až 80. let a do analýzy zahrnuje i údaje o dialogu, většinou se ale soustřeďuje na vypravěčský text.
[3] Viz F. Daneš, Americká studie o mluvené češtině, NŘ 40, 1957, s. 296–300.
[4] Srov. P. Sgall a kol., Variation in Language, Amsterdam & Philadelphia 1992.
[5] Viz J. Hronek, Obecná čeština, Praha 1972, s. 111–118.
[6] Viz N. Bermel, Register Variation and Language Standards in Czech, Studies in Slavic Linguistics 13, Munich 2000. Často zmiňované tvrzení B. Havránka (Na závěr dvouleté diskuse o obecné a hovorové češtině, SaS 24, 1963, s. 254–262), že jde o jeden tvar z deseti v oblasti slovesného tvarosloví, zde nebereme v úvahu, poněvadž se týká čistě počtu morfologických tvarů v jazykovém systému nehledě k frekvenci v textech.
[7] Existuje i termín „code mixing“, tj. míšení kódů, ke kterému se později vrátíme.
[8] Je pravda, že výslovnost v řeči bývá občas méně jasná a že se uplatňuje několik obecných tendencí, např. ke zjednodušení souhláskových skupin (vždycky-dycky) a asimilace neznělých souhlásek k jejich znělým protikladům (plakát-plagát). Tyto tendence se ale neprojevují všude a je otázkou, nakolik charakterizují OČ a nakolik mluvenou češtinu vůbec. Viz N. Bermel, d. cit. v pozn 6, s. 55.
[9] Pro podrobnější výklad situačního a komunikačního střídání viz R. Hudson, Sociolinguistics, Cambridge 1980.
[10] Z hlediska situačního je čeština často považována za jazyk diglosní, tj. disponující dvěma útvary dost odlišnými, které se uplatňují v přísně vyhraněných situacích a které existují v relacích „vysoký útvar-nízký útvar“. Definici viz C. Ferguson, Diglossia, Word 15, 1959, s. 325–340; o vhodnosti tohoto popisu pro češtinu viz F. Daneš, Pojem spisovného jazyka v dnešních společenských podmínkách, in: Jazyk a text, Praha 1999, T. Dickins, Linguistic Varieties in Czech: Problems of the Spoken Language, Slavonica 1, 1994, s. 20–46, A. Grygar-Rechzieglová, On Czech Diglossia, in: M. Grygar, ed., Czech Studies: Literature, Language, Culture, Amsterdam 1990, s. 9–29, L. Micklesen, Czech Sociolinguistic Problems, Folia Slavica 1 (3), 1978, s. 437–455, P. Sgall a kol., d. cit. v pozn. 4, N. Bermel, d. cit. v pozn. 6.
[11] P. Auer, The Pragmatics of Code-Switching: A Sequential Approach, in: L. Milroy, P. Muysken, eds., One Speaker, Two Languages: Cross-Disciplinary Perspectives on Code-Switching, Cambridge 1995, s. 115–135; J. Blom, J. Gumperz, Social Meaning in Linguistic Structure: Code-Switching in Norway, in: J. Gumperz, D. Hymes, eds., Directions in Sociolinguistics: The Ethnography of Communication, Oxford 1986 (1972), s. 407–434.
[12] P. Sgall, J. Hronek, Čeština bez příkaz, Praha 1992.
[13] L. Procházková, Oční kapky, Brno 1991, s. 53.
[14] Ch. Townsend, A Grammar of Spoken Prague Czech, Columbus 1990, H. Kučera, Phonemic Variations of Spoken Czech, Word 11 (4), 1955, s. 575–602; týž, Inquiry into Coexistent Phonemic Systems, in: Slavic Languages. American Contributions to the Fourth International Congress of Slavicists, Moscow, September 1958, S-Gravenhage, 1958, s. 169–189.
[15] K. Kravčišinová, B. Bednářová, Z výzkumu běžně mluvené češtiny, Slavica Pragensia 10, 1968, s. 305–320, D. Davidová a kol., Mluvená čeština na Moravě, Acta Facultatis Philosophicae Universitatis Ostravensis 106, Ostrava 1997.
[16] J. Kraus, Does Spoken Literary Czech Exist? in: E. Eckert, ed., Varieties of Czech, Amsterdam 1993, s. 42–49.
[17] J. Kraus a kol., Současný stav a vývojové perspektivy kodifikace spisovné češtiny, SaS 42, 1981, s. 228.
[18] O slovní zásobě a skladbě v literárním dialogu viz N. Bermel, d. cit. v pozn. 6, kapitoly 5 a 6.
[19] Je otázkou, nakolik jsou tyto rozdílné pozice a priori důležité. Pravděpodobně vyjadřují spíše zásadní rozdíl mezi výskytem variant v jednotlivých slovech, resp. kmenech, a v určitých, často se vyskytujících koncovkách adjektiv (viz N. Bermel, d. cit. v pozn. 6).
[20] Dalším důvodem tu může být poměrně nízký výskyt kmenových poloh oproti koncovkovým polohám, který by statisticky zvětšil význam každé variace u kmenů. Možnost připojení OČ koncovek k adjektivním kmenům zůstává nadále diskutovaná. Někteří badatelé tvrdí, že se v mluvě OČ koncovky připojují skoro ke každému kmenu (P. Sgall a J. Hronek zaznamenali u lingvistů mj. těch votevřenejch é, s novejma lexémama, s těma starochetitskejma textama, d. cit. v pozn. 12, s. 25); jiní naopak považují takové tvary za záměrnou stylizaci u intelektuálů určité povahy (viz např. O. Uličný, K teorii mluveného jazyka, in: K diferenciaci současného mluveného jazyka, Ostrava 1995, s. 24: „jen mluvčí stylizující se do nonkonformních póz mohou tvrdit, že spisovné prostředky jsou strnulé, nemluvné, apod.“ a dále, že smíšené veřejné projevy odrážejí „nízkou profesionalitu u umělců a některých pedagogů, kde se hlásí ke slovu puzení ke stylizaci“). Spolehlivé údaje z mluvy, které by prokázaly souvislost mezi frekvencí koncovek a jednotlivými kmeny a pomohly zdůvodnit jednu z těchto pozic, zatím chybějí.
[21] Tady záleží na jednotlivých slovech, např. Kanaďani se může považovat za spisovnější než lidi.
[22] Zatímco tvary typu pracujou a můžou se těší určité oficiální přízni, tvary typu vedem se traktují jako „substandardní“ (Příruční mluvnice češtiny, Praha 1995, s. 313), i když se plně spisovně užívaly v dřívější literatuře a v poezii (K. Gammelgaardová, osobní sdělení).
[23] Viz např. P. Sgall, Neochuzujme spisovnou češtinu, ČaL 49, 1998, s. 29
[24] Můžeme si položit otázku: Proč by hlavní postavy mluvily velice často „spisovněji“, ale občas i „obecněji“, než postavy vedlejší? Odpověď asi spočívá ve shodné narativní strategii těchto tří děl: v každém jde o poměrně vzdělanou, inteligentní hlavní postavu, s kterou by se poměrně vzdělaný, inteligentní čtenář snadno sblížil nebo s kterou by ochotně sympatizoval. Vedlejší postavy se vyskytují řidčeji, a proto jejich způsob mluvy tvoří důležitější součást jejich charakterizace, což může vést ke zdůraznění znaků osobitosti u těchto postav. Jindy ale jejich způsob mluvy odráží fakt, že je nejčastěji potkáváme v jejich oficiálních rolích, ve kterých může být obvyklý určitý způsob kombinace variant a ke kterým se reaguje stejnou předepsanou kombinací. Se značně vyšším výskytem OČ prvků mluví např. listonoš, zvědavá sousedka, prodavačka, horník a taxikář, naopak s vyšším výskytem SČ prvků mluví např. kněz, politik a lékař.
Naše řeč, volume 84 (2001), issue 1, pp. 16-30
Previous Ludmila Uhlířová: Internetový dialog jazykové poradny s veřejností (poradna@ujc.cas.cz)
Next Jihan Abou el-Seoud: Konfrontace vlastních jmen osobních v češtině a arabštině
© 2011 – HTML 4.01 – CSS 2.1